Vòng lặp, ảo tưởng (hallucinations) và bài học rút ra: Xây dựng lại Trợ lý AI trên n8n
Chúng tôi thích dùng chính sản phẩm của mình, khi xây dựng lại trợ lý AI nội bộ dù chúng thường xuyên gặp hallucinations (ảo tưởng), chúng tôi thử dùng công cụ của chính mình. Là kỹ sư lập trình, thử thách này rất hấp dẫn khi chuyển từ dòng lệnh sang xây dựng bằng quy trình tự động. Sau vài tháng, chúng tôi thành công rõ rệt và học hỏi nhiều bài học quý giá. Hy vọng qua đó, các bạn cũng có thể áp dụng hiệu quả cho việc phát triển công cụ AI.
Tại n8n, chúng tôi rất thích “uống rượu sâm panh do chính mình làm ra”, nên khi bắt tay vào xây dựng lại trợ lý AI nội bộ, chúng tôi đã quyết định thử xem liệu có thể thực hiện điều đó hoàn toàn bằng công cụ của chính mình hay không. Là những kỹ sư tư duy bằng mã lệnh, đây là một thử thách đầy hấp dẫn khi phải tạm rời xa dòng lệnh để thử nghiệm xây dựng bằng quy trình tự động hóa. Mất vài tháng để hoàn thành, nhưng cuối cùng chúng tôi đã làm được – và còn khá thành công nữa! Không những vậy, chúng tôi còn rút ra được nhiều bài học giá trị trong quá trình thực hiện. Nếu bạn đang lên kế hoạch xây dựng các công cụ AI, hy vọng trải nghiệm của chúng tôi cũng sẽ hữu ích với bạn như nó đã giúp ích cho chính chúng tôi.
Mã cứng, chỉnh sửa khó khăn
Chúng tôi từng sử dụng một trợ lý AI nội bộ được mã hóa cứng trong một thời gian dài, nhưng việc cập nhật và tinh chỉnh nó rất khó khăn, và quá phức tạp để các đồng nghiệp quản lý sản phẩm (PM) có thể tham gia. Nếu muốn chỉnh sửa logic AI, cải thiện prompt hoặc chỉ đơn giản là tối ưu hiệu suất, bạn sẽ phải dấn sâu vào mã nguồn. Về mặt kỹ thuật, đây là một sản phẩm được xây dựng vững chắc, nhưng lại không thể tiếp cận được với những người sẽ hưởng lợi nhiều nhất từ nó.
Chúng tôi vẫn rất thích những công cụ đã sử dụng trong phiên bản trợ lý AI đầu tiên, nên biết chắc rằng sẽ tiếp tục dùng LangChain để điều phối và chạy mọi thứ qua GPT-4. Nhưng mục tiêu cuối cùng của chúng tôi là thử xem liệu một use case AI phức tạp như vậy có thể được xây dựng hoàn toàn trên nền tảng n8n hay không mà không gây nên hallucinations.
Trợ lý AI dễ bị hallucinations (ảo tưởng)
Trợ lý AI của n8n được xây dựng để phục vụ ba mục đích chính:
- Gỡ lỗi cho người dùng khi gặp lỗi
- Trả lời các câu hỏi dạng ngôn ngữ tự nhiên trong giao diện trò chuyện
- Hỗ trợ người dùng thiết lập thông tin đăng nhập
Ở phía backend, chúng tôi vận hành hai nguồn vector lớn tạo nên Cơ sở Kiến thức (Knowledge Base – KB) nội bộ — một là tài liệu chính thức, còn lại là sử dụng diễn đàn n8n. Chúng tôi hướng dẫn trợ lý đọc tài liệu trên website trước để giảm hiện tượng “ảo giác” (hallucinations), sau đó mới tìm đến Diễn đàn để khai thác thêm thông tin, vì nguồn thông tin tại diễn đàn thường không được trình bày đủ chính xác mà rất hay xảy ra hallucinations
Dữ liệu được xử lý thành các đoạn nhỏ, mỗi đoạn được lưu cùng với ngữ cảnh, giúp trợ lý hiểu đoạn đó nằm ở đâu trong tài liệu và bối cảnh xung quanh nó. Tất nhiên, việc này cũng được tự động hóa bằng các workflow n8n — ba lần một tuần, hệ thống tự động quét lại tài liệu để cập nhật cơ sở dữ liệu. Đồng thời, chúng tôi cũng quét Diễn đàn để lấy các câu hỏi có câu trả lời đầy đủ và kết hợp chúng vào KB. Tự dùng sản phẩm của chính mình mà! 😄
Cả Dịch vụ AI và hệ thống nội bộ nơi chứa các workflow đều có môi trường phát triển và môi trường sản xuất riêng biệt, nên chúng tôi có thể làm việc mà không ảnh hưởng trực tiếp đến hệ thống đang chạy chính thức.
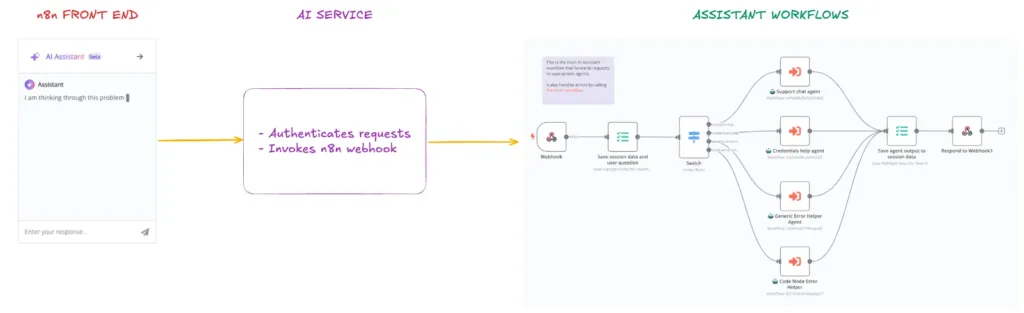
Dưới đây là tổng quan các thành phần chính của trợ lý:
- Giao diện n8n (Frontend): Tất cả tin nhắn người dùng gửi từ khung trò chuyện sẽ được gửi đến Dịch vụ AI – một dịch vụ web riêng được lưu trữ nội bộ.
- Dịch vụ AI (AI Service): Xử lý xác thực cho các yêu cầu gửi đến, sau đó gọi webhook của n8n cũng với xác thực để đảm bảo workflow chỉ nhận yêu cầu từ dịch vụ AI.
- Workflow của Trợ lý: Được lưu trữ trong hệ thống nội bộ. Có một workflow chính (Gateway) nhận webhook và điều hướng đến agent cụ thể tùy theo chế độ người dùng.
Bên trong, chúng tôi có bốn agent riêng biệt xử lý các trường hợp sử dụng khác nhau của Trợ lý. Cách tiếp cận này cho phép mỗi agent nhận đúng ngữ cảnh đầu vào và công cụ phù hợp. Khi người dùng khởi động Trợ lý, chúng tôi sử dụng node Switch của n8n để định tuyến đến một trong bốn agent khác nhằm hạn chế hallucinations (ảo tưởng). Điểm trừ duy nhất là khi một agent đã bắt đầu cuộc trò chuyện, người dùng sẽ không thể chuyển sang agent khác trong cùng một phiên, và cần khởi động lại để chuyển đổi.
Gỡ lỗi lỗi người dùng
Trợ lý lỗi tổng quát: Được kích hoạt khi người dùng nhấn nút Ask Assistant từ bảng kết quả của node khi xảy ra lỗi. Agent này chuyên xử lý lỗi từ các node nói chung, có thông tin ngữ cảnh về lỗi, và được quyền truy cập vào tài liệu n8n cũng như các câu trả lời từ Diễn đàn.
Trợ lý lỗi Code Node: Chuyên xử lý các lỗi xảy ra trong Code Node. Agent này được khởi chạy khi người dùng nhấn Ask Assistant tại node có lỗi trong Code Node. Nó có quyền truy cập vào mã nguồn của người dùng và tài liệu n8n. Bên cạnh việc trả lời câu hỏi, agent này còn có thể đề xuất chỉnh sửa mã và áp dụng trực tiếp vào node đang mở nếu người dùng đồng ý.
Trả lời câu hỏi dạng hội thoại ngôn ngữ tự nhiên
Trợ lý hỗ trợ: Phản hồi yêu cầu khi người dùng mở khung trò chuyện và bắt đầu đặt câu hỏi. Agent này có ngữ cảnh về những gì người dùng đang xem (workflow và node), đồng thời được truy cập vào tài liệu n8n và câu trả lời từ Diễn đàn.
Hỗ trợ người dùng thiết lập thông tin đăng nhập
Trợ lý thông tin đăng nhập: Được kích hoạt khi người dùng nhấn Ask Assistant trong cửa sổ thiết lập credentials. Agent này có ngữ cảnh về node hiện tại và loại credentials người dùng muốn thiết lập, đồng thời được truy cập vào tài liệu n8n.
Triển khai thực tế
Một trong những thử thách lớn nhất khi làm việc với AI là phản hồi của nó đôi khi rất bất ngờ. Bạn hỏi một câu thì có thể được trả lời chính xác, nhưng chỉ cần thay đổi nhỏ như tên hoặc con số trong prompt, thì kết quả có thể hoàn toàn khác.
Để giải quyết vấn đề này, chúng tôi bắt đầu đơn giản — kiểm tra agent bằng prompt như “tại sao tôi thấy thông báo này?”. Chúng tôi nhanh chóng nhận ra rằng cần cung cấp nhiều ngữ cảnh hơn, vì trợ lý không tự động hiểu nội dung mà người dùng đang nhìn thấy trước khi tìm kiếm trong KB.
Vì vậy, chúng tôi xây dựng một công cụ gọi là workflow info, cho phép trợ lý thu thập thông tin từ workflow cụ thể.
Giờ đây, khi người dùng đặt câu hỏi về workflow hoặc lỗi cụ thể mà không mô tả rõ, trợ lý có thể sử dụng công cụ workflow info để lấy lỗi hoặc tiến trình từ những gì người dùng đang nhìn thấy. Hiện tại, trợ lý trong khung chat hỗ trợ có thể trả lời chính xác bằng cách đọc các schema người dùng đang xem và sử dụng chúng làm cơ sở tìm kiếm.
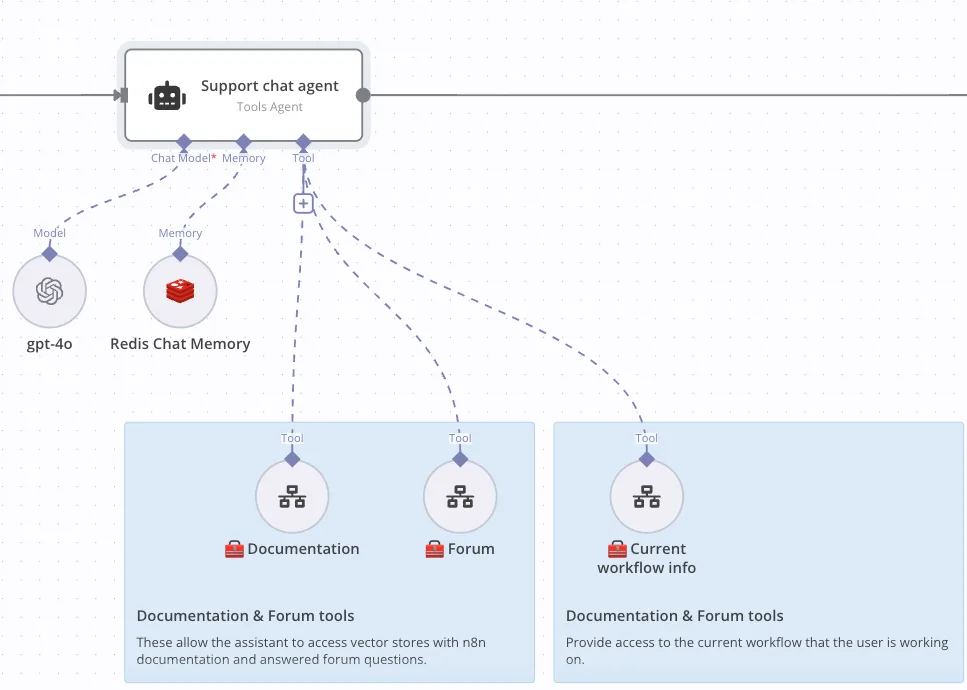
Dưới đây là một ví dụ, minh họa cách agent sử dụng các công cụ khác nhau để gỡ lỗi cho người dùng.
AI đánh giá AI để tránh ảo tưởng (hallucinations)
Chúng tôi lưu lại các lần thực thi, vì vậy tất cả các trace đều có sẵn trực tiếp trong n8n, điều này giúp chúng tôi có một bộ dữ liệu nội bộ tuyệt vời để đánh giá thử nghiệm và điều chỉnh prompt. Với bộ dữ liệu trace phong phú như vậy, chúng tôi tự hỏi: “Sao không dùng AI để tăng tốc quá trình cải tiến?” – và bắt đầu triển khai một mô hình ngôn ngữ lớn (LLM) để đánh giá các phản hồi mà chính LLM của chúng tôi tạo ra.
Tuy nhiên, chúng tôi mắc một lỗi cơ bản khi đưa cùng một tập hướng dẫn cho cả Trợ lý và Giám khảo: tạo phản hồi hữu ích, có thể hành động và ngắn gọn. Kết quả là Giám khảo chấm điểm hoàn hảo cho mọi câu trả lời. Vì vậy, chúng tôi tiếp tục điều chỉnh lại framework này.
Nội bộ, chúng tôi có một dự án kiểm thử tuỳ chỉnh trong LangSmith – nơi chúng tôi có thể chạy Trợ lý với các yêu cầu mẫu từ trace và nhận điểm chất lượng cho câu trả lời. Điều này cho phép chúng tôi thử nghiệm nhanh các prompt và mô hình khác nhau. Phải mất khá nhiều thử nghiệm để xây dựng được một hệ thống đánh giá đáng tin cậy, và mỗi lần thay đổi thứ gì đó, chúng tôi lại phải kiểm thử lại. Nhưng giờ đây, với gần 50 tình huống sử dụng, chúng tôi có thể đánh giá chính xác hơn tác động của các thay đổi đến chất lượng phản hồi.
Hiện tại, LLM Giám khảo sẽ nhận một prompt từ người dùng cùng phản hồi từ Trợ lý, và đưa ra đánh giá dựa trên một bộ tiêu chí: “phản hồi có bao gồm X không, có phải ưu tiên cao không, có thể hành động được không”, v.v. Cho đến nay, chất lượng có vẻ tốt hơn mô hình cũ của chúng tôi!
Bài học rút ra
Chậm một chút cũng không sao, càng nhanh tỷ lệ hallucinations càng nhiều
Chúng tôi sớm nhận ra rằng người dùng không ngại chờ vài giây để nhận được câu trả lời hữu ích. Ban đầu, chúng tôi nghĩ rằng việc mất 10 giây để phản hồi sẽ làm người dùng nản lòng – nhưng hóa ra không phải vậy. Mặc dù thời gian phản hồi có tăng nhẹ, nhưng tỷ lệ giải quyết lỗi không hề giảm.
Lặp lại, lặp lại, lặp lại!
Là kỹ sư, chúng tôi thường dựa vào cảm giác để điều chỉnh mã – bạn có thể thấy chỗ cần thay đổi và xem kết quả ngay. Nhưng với AI, chỉ cần thay đổi cách đặt câu hỏi một chút là câu trả lời đã khác hoàn toàn. Và đôi khi bạn chỉnh prompt để cải thiện một tình huống, thì ba tình huống khác lại tệ đi!
AI vốn không mang tính quyết định cao, nên việc đánh giá và cải tiến phản hồi cần một tư duy hoàn toàn khác. Thử – sai – điều chỉnh đã trở thành tiêu chuẩn mới khi chúng tôi tinh chỉnh mọi khía cạnh của trợ lý để tìm ra điều phù hợp. Dù mất thời gian, nhưng nỗ lực đó đã đem lại thành quả: chất lượng phản hồi cao hơn, và thời gian phản hồi thì ngày càng được cải thiện.
Suy nghĩ vượt ra ngoài code
Chúng tôi là kỹ sư, nên việc từ bỏ tư duy “chỉ viết code” và chuyển sang xây dựng bằng workflow ban đầu khá khó khăn, đặc biệt AI hallucinations rất thường xuyên khiến các workflow rất hay bị ảnh hưởng. Nhưng dự án này đã hoàn toàn thay đổi suy nghĩ của chúng tôi về cách tiếp cận low-code – việc xây dựng và triển khai lại trợ lý AI dễ hơn rất nhiều so với tưởng tượng, và chúng tôi thực sự ấn tượng với mức độ thành công của nó, ngay cả khi xử lý dữ liệu quy mô lớn.
Điều gì tiếp theo với N8n và AI liên tục gặp Halluciation
Việc kết quả trả ra từ AI không ổn định và dễ bị hallucinations (ảo tưởng) rất khó để khắc phục hoàn toàn, đơn giản vì toàn bộ lý thuyết về LLM chạy trên tỷ lệ và tỷ lệ thì hiếm khi đạt full 100%, càng kéo dài input thì tỷ lệ hallucinations sẽ càng cao.
Nhưng tất nhiên ta có thể giám định lại nó đến khi đạt một mức giới hạn cho phép. Ở đây việc lồng một prompt qua một LLM và mang kết quả sang 1 LLM khác đánh giá hiện đang là cách tốt nhất. Nếu bạn vẫn đang vướng về tích hợp AI không ổn định, hay ảo tưởng (hallucinations) ra kết quả , hãy trao đổi với chúng tôi hoặc tìm các thông tin cập nhật tại đây