Xây dựng chatbot RAG bằng n8n
Bạn đã bao giờ ước có một chatbot có thể trả lời các câu hỏi cụ thể về dữ liệu hoặc tài liệu của bạn, thay vì chỉ tạo ra những câu trả lời chung chung và thiếu chính xác? Hãy xây dựng một chatbot thực sự hiểu dữ liệu của bạn với Retrieval Augmented Generation (RAG)!
Trong bài viết này, chúng ta sẽ cùng tìm hiểu cách Retrieval Augmented Generation (RAG) giúp bạn xây dựng các chatbot chuyên biệt, vượt ra khỏi giới hạn của các cuộc trò chuyện thông thường. Thay vì chỉ dựa vào các phản hồi chung chung, các chatbot sử dụng RAG sẽ tận dụng các nguồn kiến thức bên ngoài để đưa ra các câu trả lời chính xác và mang tính thông tin cao cho những truy vấn phức tạp.
Chúng tôi sẽ phân tích các khái niệm cốt lõi của RAG và xem xét một số ví dụ thực tế về quy trình làm việc với RAG. Và đây không chỉ là lý thuyết – chúng tôi sẽ trình bày cách triển khai RAG bằng n8n, một công cụ tự động hóa quy trình làm việc mạnh mẽ.
Khi kết thúc bài viết này, bạn sẽ có đủ kiến thức và công cụ để tự xây dựng chatbot RAG của riêng mình.
RAG được sử dụng trong chatbot như thế nào?
Retrieval Augmented Generation (RAG) trong các chatbot là một kỹ thuật mạnh mẽ, kết hợp sức mạnh của các mô hình ngôn ngữ lớn (LLMs) với các nguồn kiến thức bên ngoài nhằm tạo ra các phản hồi phù hợp hơn và quan trọng nhất là chính xác hơn.
RAG đặc biệt hữu ích trong các tình huống mà mô hình ngôn ngữ cần truy cập và sử dụng các thông tin không có trong dữ liệu huấn luyện ban đầu, ví dụ như khi cần trả lời các câu hỏi về các lĩnh vực chuyên ngành cụ thể, các tài liệu nội bộ, hoặc dữ liệu không được công bố công khai.
Các chatbot AI có thể sử dụng RAG để truy cập và xử lý thông tin từ nhiều nguồn khác nhau, bao gồm dữ liệu phi cấu trúc như tài liệu văn bản, trang web, bài đăng trên mạng xã hội, cũng như dữ liệu có cấu trúc như cơ sở dữ liệu và đồ thị tri thức. Điều này cho phép chúng đưa ra các câu trả lời đầy đủ và hữu ích hơn, cá nhân hóa trải nghiệm người dùng, luôn cập nhật với thông tin mới nhất, và đặc biệt là phản hồi dựa trên tài liệu nội bộ.
Sự khác biệt giữa tìm kiếm ngữ nghĩa và RAG là gì?
Dù cả tìm kiếm ngữ nghĩa và RAG đều hướng đến mục tiêu cải thiện khả năng truy xuất thông tin, nhưng chúng khác nhau về cách tiếp cận và khả năng.
Tìm kiếm ngữ nghĩa tập trung vào việc hiểu ý định và ngữ cảnh của truy vấn người dùng để truy xuất thông tin phù hợp. Nó sử dụng các kỹ thuật như xử lý ngôn ngữ tự nhiên (NLP) để phân tích ý nghĩa phía sau các từ ngữ và xác định các khái niệm có liên quan. Bạn có thể hình dung đây như một công cụ tìm kiếm thông minh hơn, vượt ra ngoài việc chỉ khớp từ khóa.
RAG thì phát triển dựa trên nền tảng tìm kiếm ngữ nghĩa bằng cách bổ sung thành phần tạo sinh. Nó không chỉ truy xuất thông tin liên quan mà còn sử dụng mô hình ngôn ngữ lớn để tổng hợp và tạo ra một câu trả lời toàn diện dựa trên thông tin đã truy xuất. Nhờ đó, RAG có thể cung cấp các phản hồi ngắn gọn và giống như con người hơn, thay vì chỉ đơn giản liệt kê các kết quả tìm được.
Hãy tưởng tượng bạn cần tìm thông tin về một mã lỗi cụ thể trong một tài liệu kỹ thuật dài. Tìm kiếm ngữ nghĩa sẽ giúp bạn xác định được các phần có liên quan trong tài liệu. RAG sau đó sẽ lấy các đoạn đó, tổng hợp thông tin, và cung cấp cho bạn một giải thích ngắn gọn về lỗi và các cách khắc phục có thể.
Cách xây dựng chatbot RAG với n8n
Giờ là lúc biến lý thuyết thành thực hành bằng cách xây dựng một chatbot RAG với khả năng tự động hóa quy trình bằng giao diện trực quan mạnh mẽ của n8n. Trong ví dụ này, chúng ta sẽ tạo một chatbot tài liệu API dành cho GitHub API, nhằm minh họa cách n8n đơn giản hóa quá trình kết nối với nguồn dữ liệu, cơ sở dữ liệu vector và mô hình ngôn ngữ lớn (LLM). Đây là một ví dụ thực hành, hướng dẫn bạn từng bước, từ trích xuất dữ liệu, lập chỉ mục cho đến tạo giao diện trò chuyện thân thiện với người dùng.
Điều kiện cần trước khi bắt đầu
Trước khi bắt tay xây dựng, hãy đảm bảo bạn đã chuẩn bị đủ các yêu cầu sau:
Tài khoản n8n:
Bạn cần có tài khoản n8n để tạo và vận hành các workflow. Nếu chưa có, bạn có thể đăng ký một tài khoản trên nền tảng n8n Cloud, hoặc tự triển khai (self-hosted) n8n trên máy chủ riêng.
Tài khoản OpenAI và API key:
Chúng ta sẽ sử dụng các mô hình của OpenAI để tạo embeddings và sinh phản hồi. Bạn cần có một tài khoản OpenAI và lấy API key. Bạn có thể tham khảo trang tài liệu chính thức của n8n để biết cách thiết lập thông tin đăng nhập OpenAI.
Tài khoản Pinecone và API key:
Pinecone sẽ là cơ sở dữ liệu vector được sử dụng để lưu trữ và truy xuất các embeddings từ tài liệu API. Bạn có thể tạo một tài khoản miễn phí trên trang chủ Pinecone và xem tài liệu hướng dẫn thiết lập thông tin kết nối Pinecone với n8n.
Kiến thức cơ bản về cơ sở dữ liệu vector:
Không bắt buộc, nhưng nếu bạn đã hiểu khái niệm cơ bản về cơ sở dữ liệu vector thì sẽ rất hữu ích. Bạn có thể đọc tài liệu giới thiệu của n8n về chủ đề này tại đây: Sử dụng Vector Databases trong n8n.
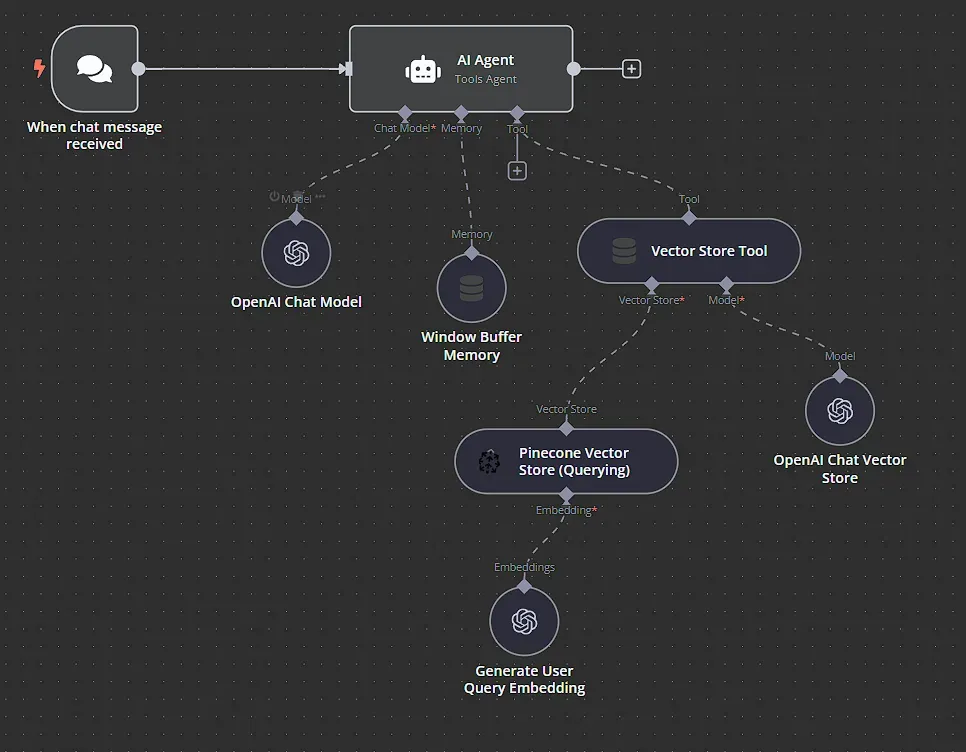
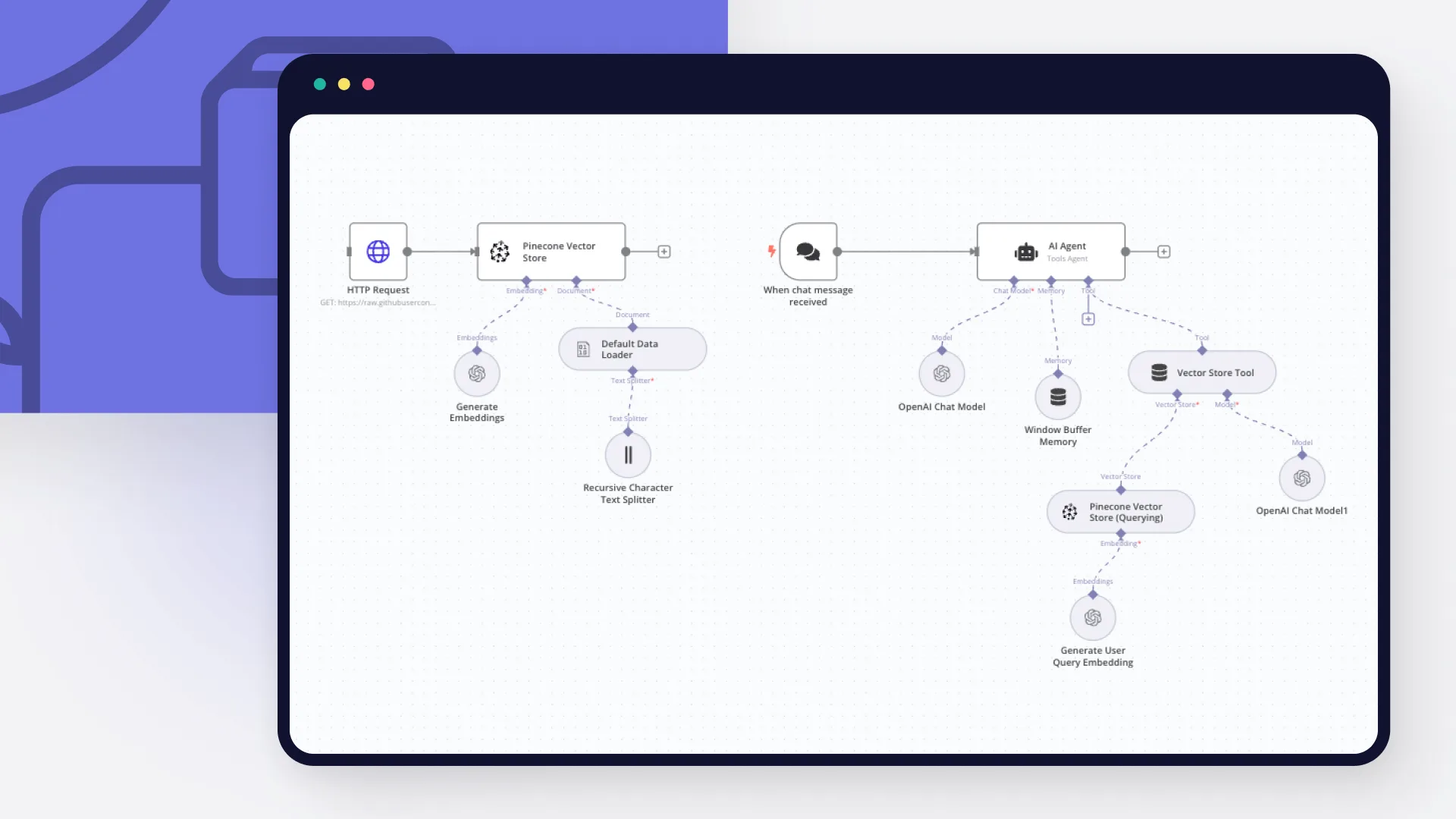
Bước 1: Thiết lập nguồn dữ liệu và trích xuất nội dung
Workflow mà chúng ta xây dựng sẽ gồm hai phần chính:
- Phần đầu tiên xử lý việc lấy dữ liệu và lập chỉ mục vào cơ sở dữ liệu vector Pinecone.
- Phần thứ hai sẽ xử lý việc trả lời câu hỏi từ người dùng thông qua chatbot AI.
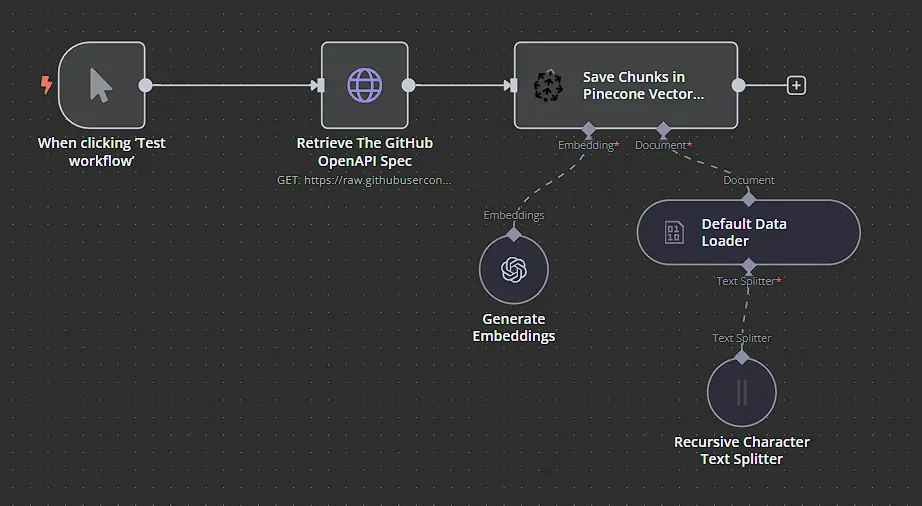
Sử dụng node HTTP Request, chúng ta đang lấy tài liệu OpenAPI 3.0 từ GitHub. Chúng ta chỉ cần sử dụng URL raw của GitHub để lấy file JSON cho kho lưu trữ. Để mặc định tất cả các tùy chọn còn lại.
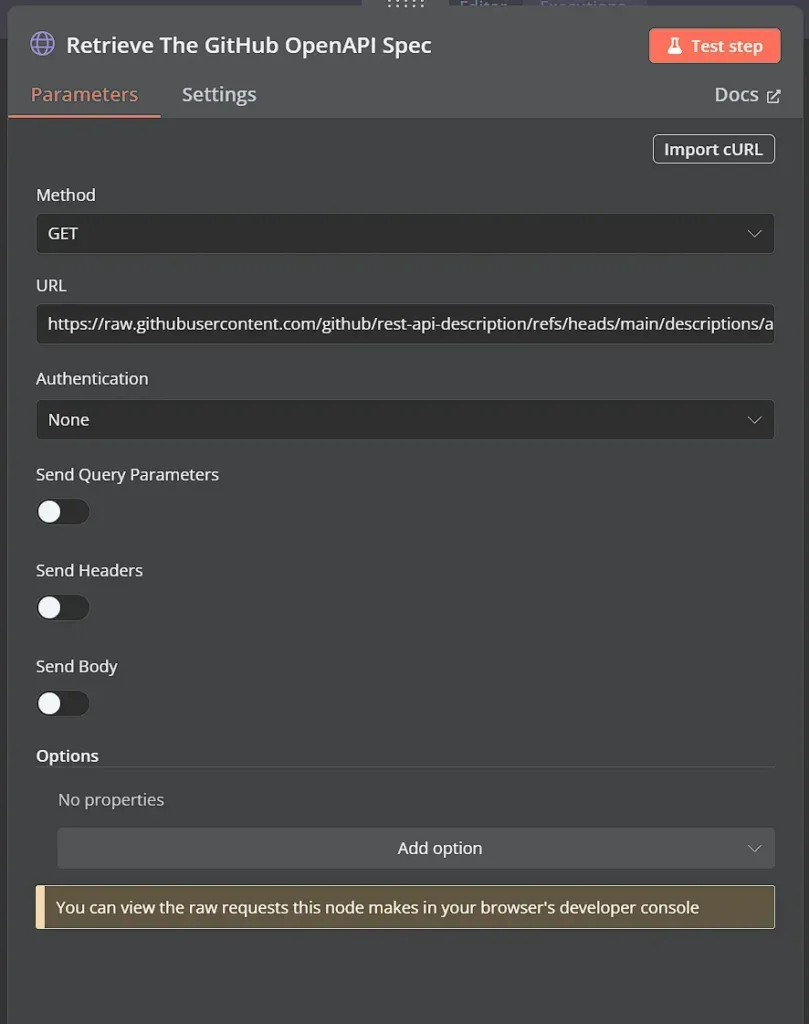
Node này thực hiện một yêu cầu GET tới URL đã chỉ định, nơi trỏ đến bản JSON thô của tài liệu đặc tả API GitHub. Phản hồi sẽ là toàn bộ tệp đặc tả OpenAPI. Tệp này sẽ được sử dụng trong bước tiếp theo.
Bước 2: Tạo embeddings
Trong bước quan trọng này, chúng ta chuyển đổi các đoạn văn bản từ tài liệu API thành các biểu diễn vector số, được gọi là embeddings. Những embeddings này nắm bắt ý nghĩa ngữ nghĩa của từng đoạn văn bản, cho phép chúng ta thực hiện các tìm kiếm tương đồng sau này. Chúng ta có thể làm điều này bằng cách sử dụng node Pinecone Vector Store.
Sau đó, chúng ta cần kết nối node Embeddings OpenAI với node Pinecone Vector Store.
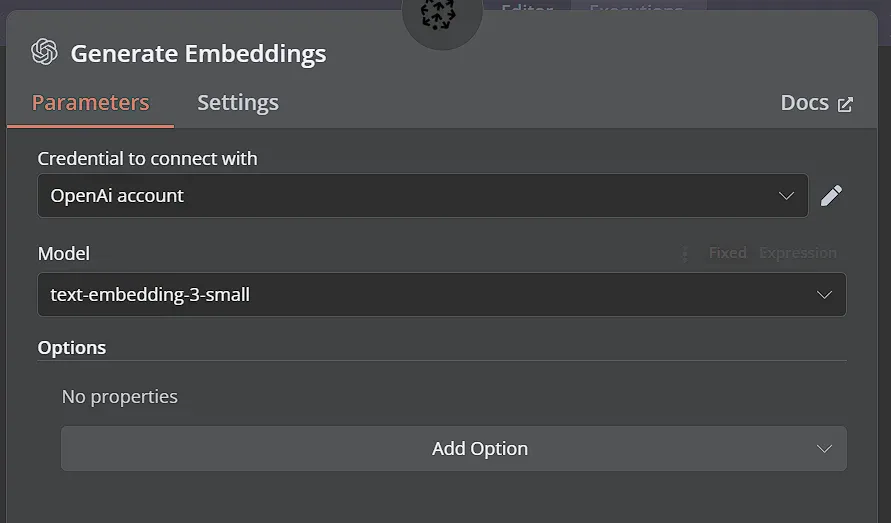
Node này sẽ nhận các đoạn văn bản và tạo ra các vector embeddings tương ứng bằng cách sử dụng mô hình embedding của OpenAI. Sử dụng thông tin đăng nhập OpenAI của bạn và chọn mô hình text-embedding-3-small.
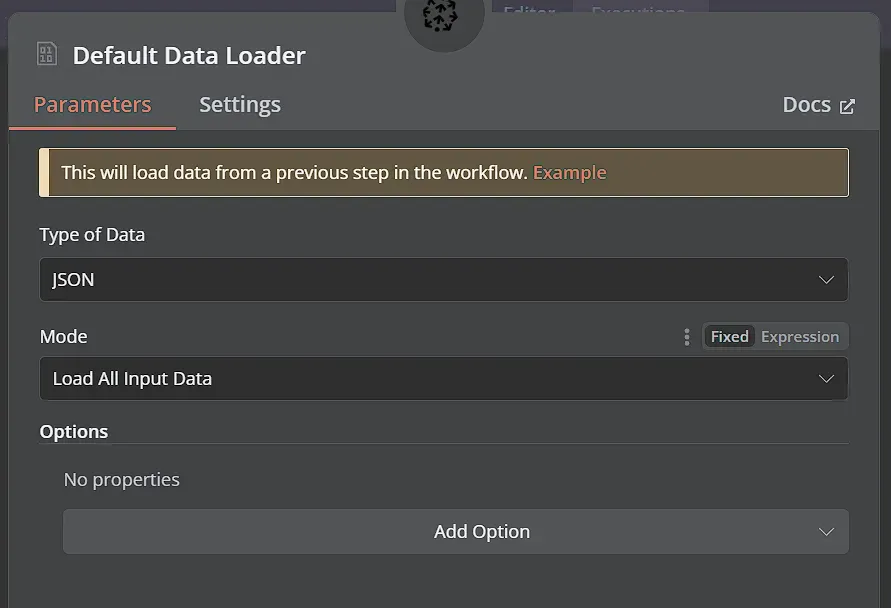
Chúng ta cũng cần kết nối node Default Data Loader và kết nối node Recursive Character Text Splitter vào node đó. Bạn có thể để tất cả các thiết lập mặc định.
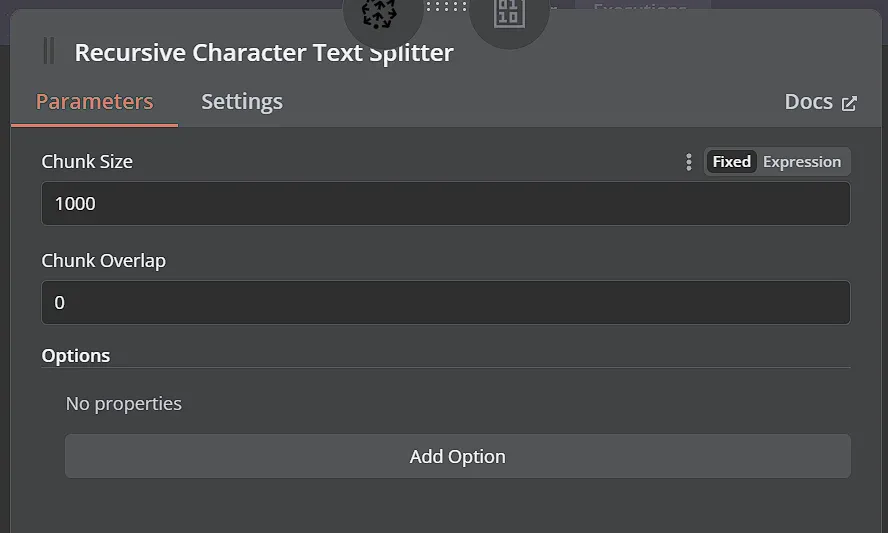
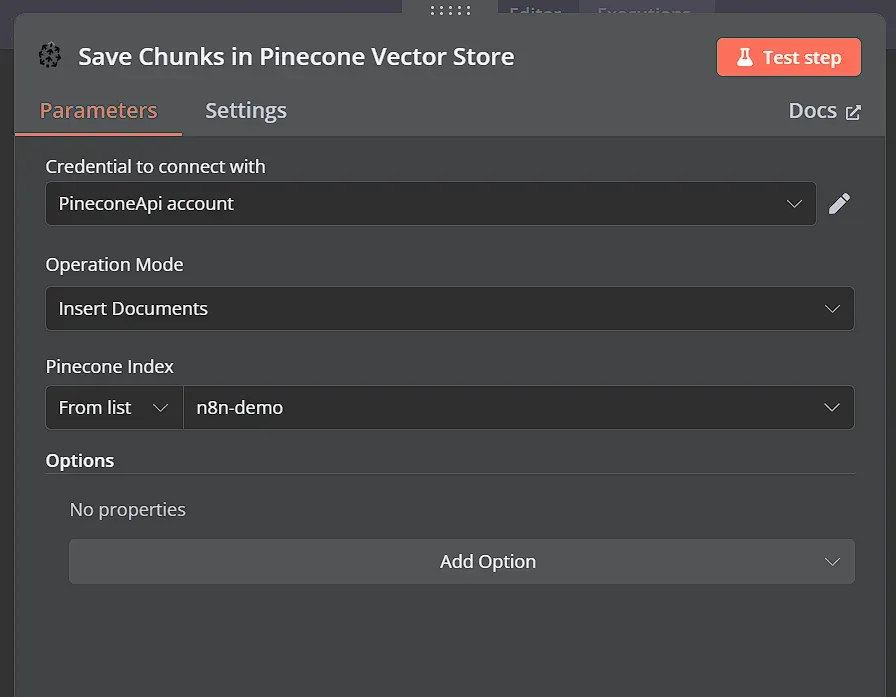
Bước 3: Lưu tài liệu và embeddings vào Pinecone vector store
Bây giờ bạn có thể chạy phần này của workflow. Quá trình này có thể mất một thời gian để tạo tất cả các embeddings và lưu chúng vào Pinecone, đặc biệt là nếu tệp API specification lớn. Sau khi hoàn thành, bảng điều khiển Pinecone của bạn sẽ hiển thị một số dữ liệu trong vector store đó.
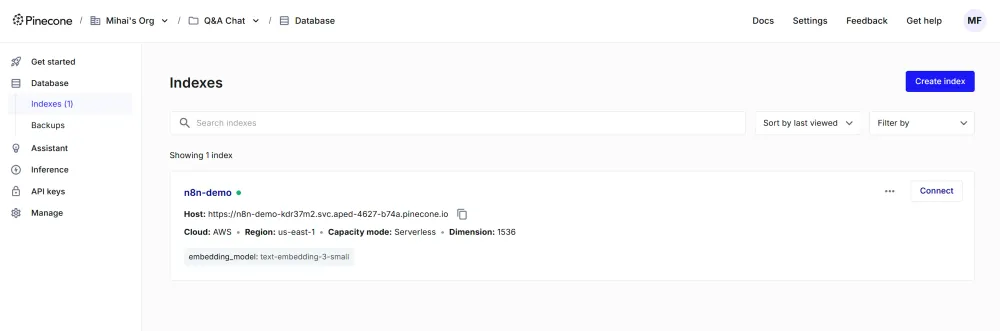
Bước 4: Xây dựng logic chính của chatbot
Với API specification đã được lập chỉ mục trong vector database, bây giờ chúng ta có thể thiết lập phần truy vấn và tạo phản hồi của workflow. Quá trình này bao gồm việc nhận câu hỏi của người dùng, tìm kiếm các tài liệu liên quan trong vector store và tạo ra một phản hồi sử dụng LLM.
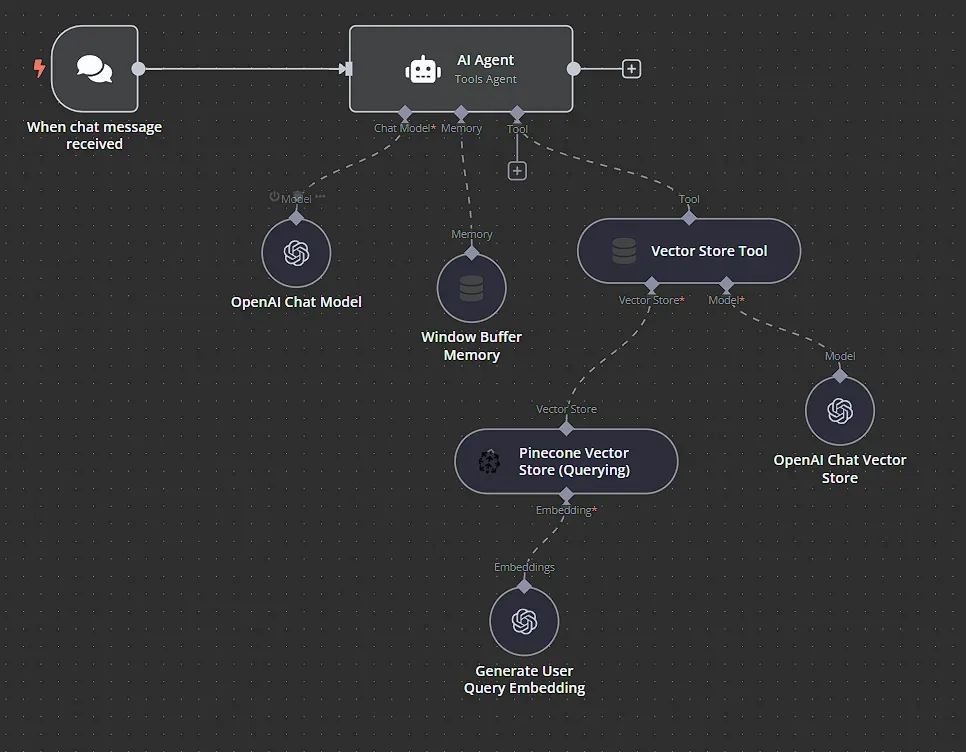
Sử dụng node Chat Trigger để nhận đầu vào từ người dùng. Node này hoạt động như điểm vào cho sự tương tác của người dùng, kích hoạt workflow khi nhận được tin nhắn trò chuyện mới. Hãy để tất cả các cài đặt ở mặc định cho bây giờ.
Sau đó, chúng ta kết nối node Chat Trigger với node AI Agent. Node này điều phối các bước truy xuất và tạo ra phản hồi. Nó nhận câu hỏi của người dùng và các tài liệu liên quan, sau đó gọi LLM để tạo ra câu trả lời.
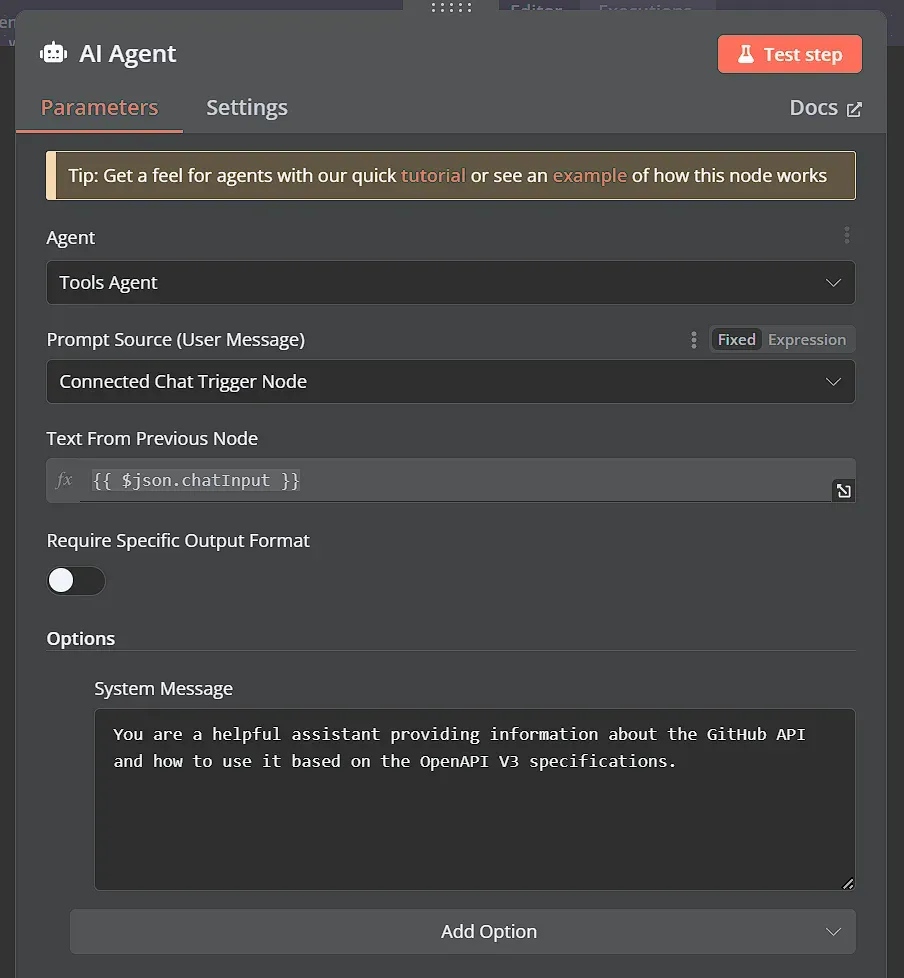
Chúng ta có thể chọn loại Agent là Tools Agent. Chúng ta cũng có thể thiết lập một System Message, thông điệp này sẽ được kết hợp với đầu vào của người dùng để tạo thành prompt cho LLM. Dưới đây là một ví dụ đơn giản về hệ thống message prompt:
“Bạn là một trợ lý hữu ích cung cấp thông tin về GitHub API và cách sử dụng nó dựa trên các thông số kỹ thuật OpenAPI V3.”
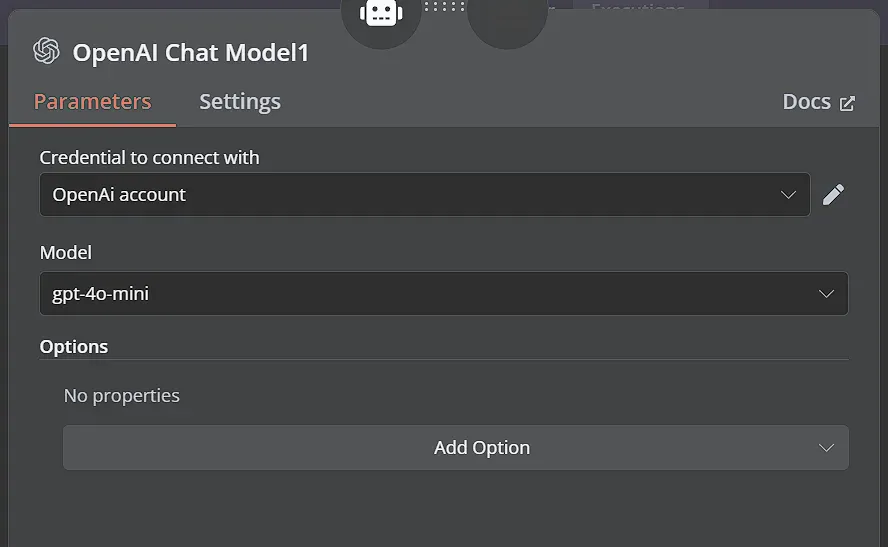
Tiếp theo, kết nối node AI Agent với node OpenAI Chat Model. Node này chịu trách nhiệm nhận câu hỏi của người dùng, cùng với các đoạn văn bản đã được truy xuất, và sử dụng LLM của OpenAI để tạo ra câu trả lời cuối cùng, đầy đủ.
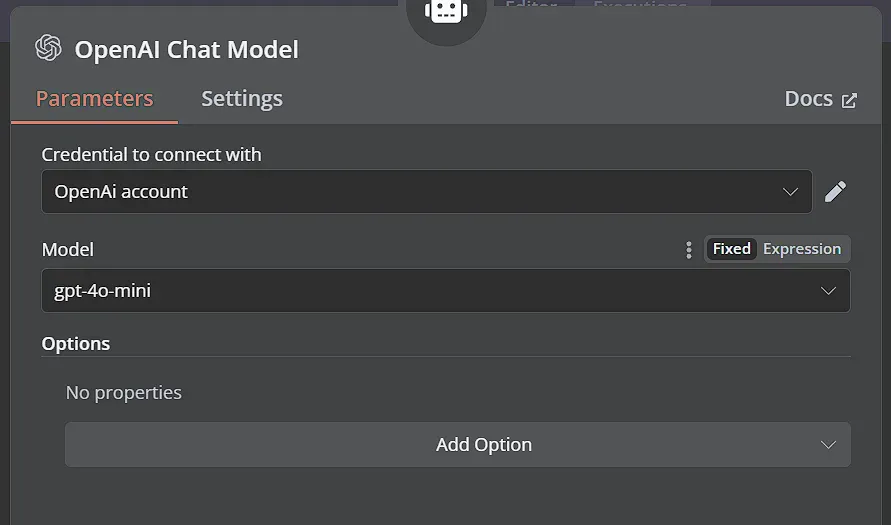
Chọn thông tin đăng nhập OpenAI của bạn và từ menu Model, chọn mô hình gpt-4o-mini hiệu quả.
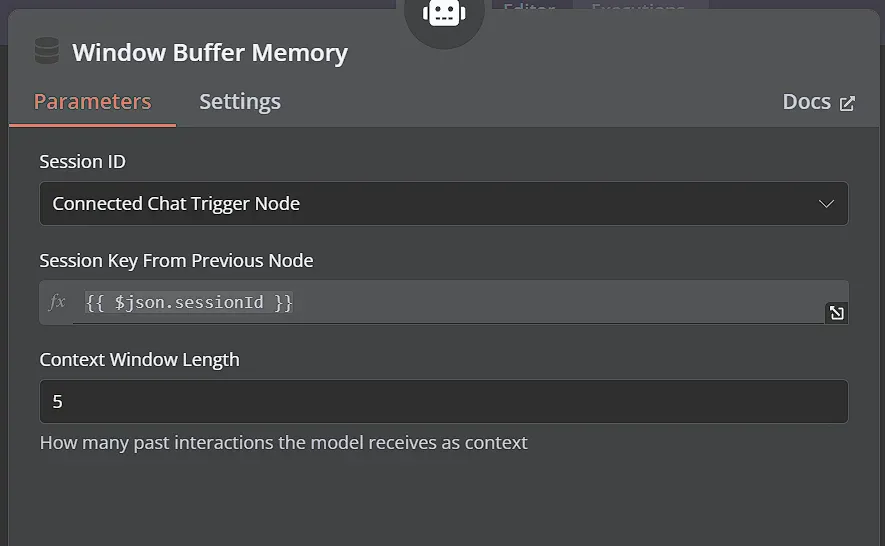
Kết nối node Window Buffer Memory với node AI Agent. Node này cung cấp bộ nhớ ngắn hạn cho cuộc trò chuyện, giúp LLM trả lời các câu hỏi tiếp theo và sử dụng các prompt và câu trả lời trước đó để cải thiện các phản hồi của nó. Bạn có thể để tất cả các thiết lập ở mặc định tại đây.
4o mini
Bước 5: Lấy thông tin bằng công cụ vector store
Bây giờ là phần quan trọng giúp chuyển đổi chatbot này thành một RAG chatbot thay vì một chatbot AI thông thường!
Kết nối một node Vector Store Tool với node AI Agent. Node này sử dụng embedding của câu hỏi người dùng để thực hiện tìm kiếm tương đồng với các embedding của các đoạn API specification đã được chỉ mục.
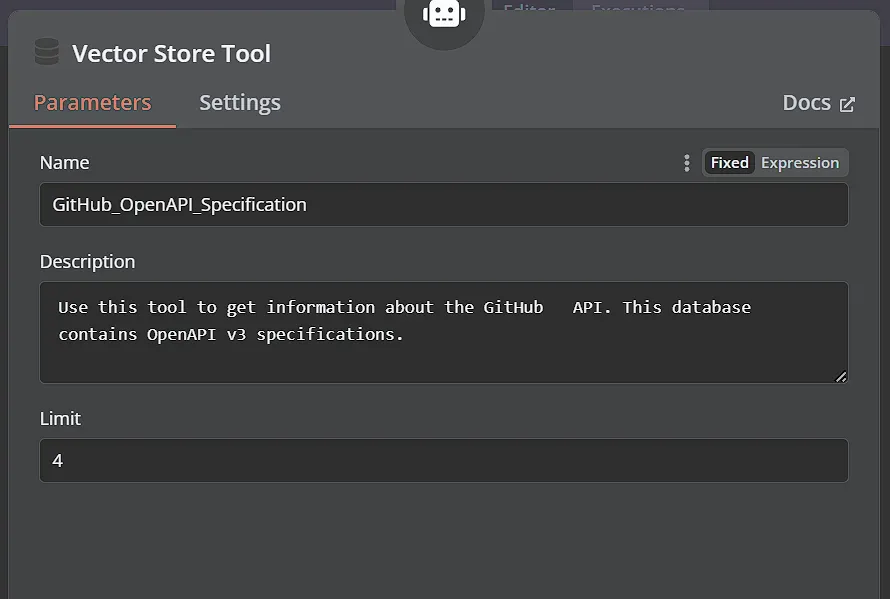
Đặt tên cho công cụ này một cách mô tả và thêm mô tả để LLM hiểu khi nào sử dụng công cụ này. Ví dụ, bạn có thể sử dụng mô tả sau:
Sử dụng công cụ này để lấy thông tin về GitHub API. Cơ sở dữ liệu này chứa các đặc tả OpenAPI v3.
Chúng ta cũng có thể giới hạn số lượng kết quả mà chúng ta lấy từ vector store, chỉ lấy 4 kết quả liên quan nhất cho câu hỏi của người dùng.
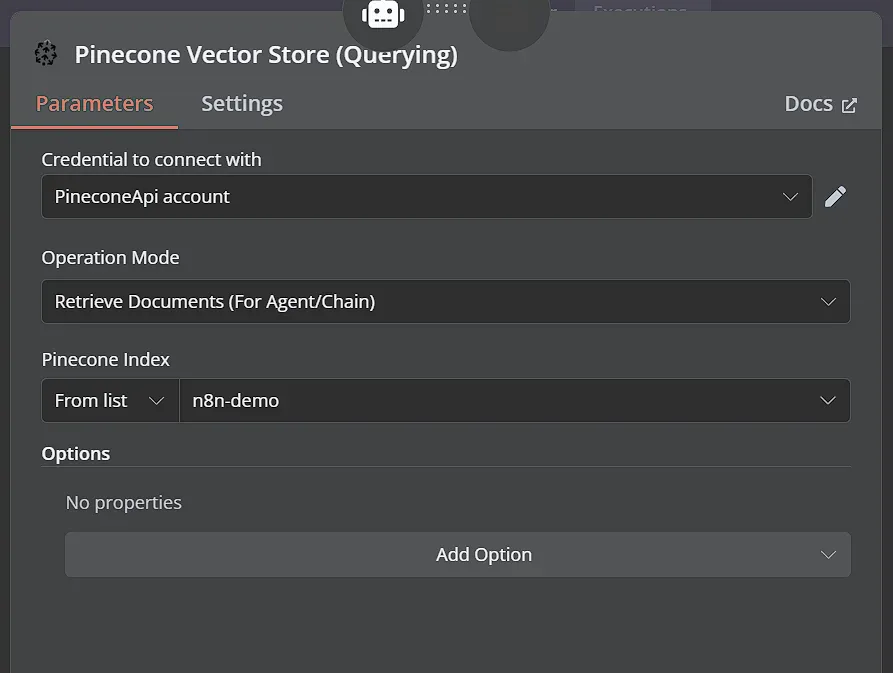
Sau đó, kết nối node Pinecone Vector Store, lần này thiết lập Operation Mode là Retrieve Documents (For Agent/Chain) và kết nối lại node Embeddings OpenAI mà chúng ta đã sử dụng trước đó, đảm bảo rằng model text-embedding-3-large được chọn. Cấu hình này sẽ tạo embeddings cho câu hỏi của người dùng, cho phép so sánh với tất cả các embeddings trong vector store của bạn.
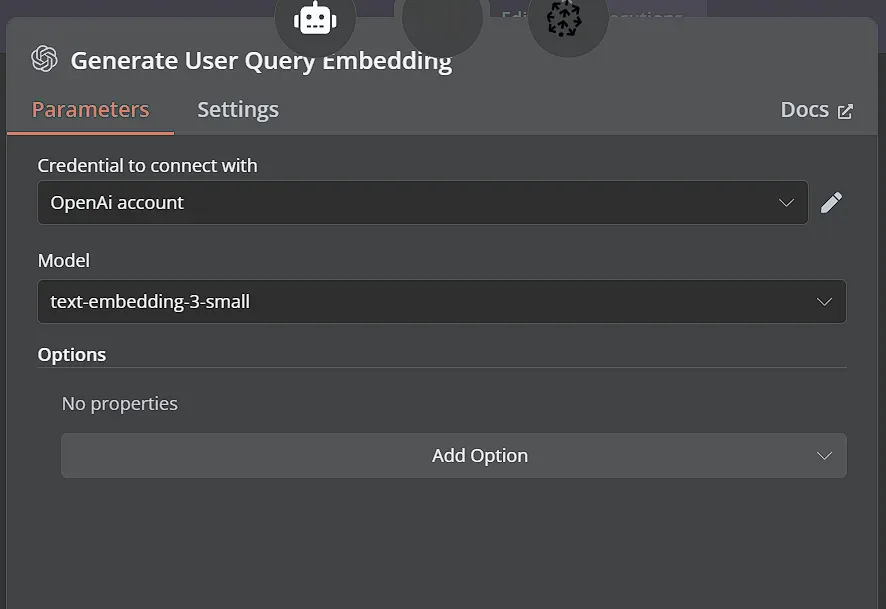
Cuối cùng, kết nối thêm một node OpenAI Chat Model. Node này sẽ tóm tắt các phần văn bản đã lấy từ cơ sở dữ liệu, cung cấp ngữ cảnh cho câu trả lời cuối cùng.
Bạn có thể sử dụng cùng một model gpt-4o-mini ở đây.
Bước 6: Kiểm tra chatbot RAG của bạn
Và bạn đã xong!
Bây giờ bạn đã cấu hình xong các thành phần cốt lõi của chatbot GitHub API sử dụng công nghệ RAG.
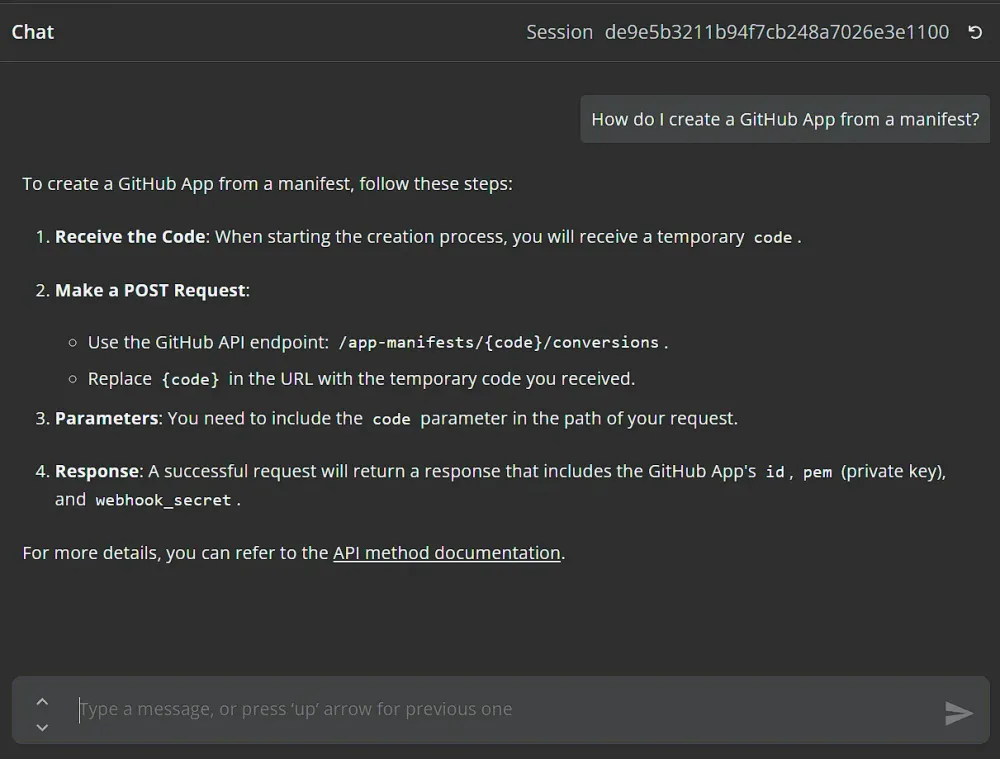
Để kiểm tra, đơn giản chỉ cần nhấp vào nút Chat nằm ở dưới cùng của trình chỉnh sửa n8n. Điều này sẽ mở giao diện trò chuyện, nơi bạn có thể bắt đầu tương tác với bot của mình. Thử hỏi câu hỏi sau: “Làm thế nào để tạo GitHub App từ manifest?”. Bạn sẽ ngạc nhiên khi thấy chatbot lấy thông tin liên quan từ đặc tả API GitHub và cung cấp cho bạn giải pháp chi tiết, từng bước, sử dụng API. Điều này chứng minh sức mạnh của RAG và cách n8n giúp bạn dễ dàng xây dựng các ứng dụng AI phức tạp.
4o mini
N8n Academy: Kết luận
Qua hướng dẫn trên, chúng tôi tin rằng các bạn có thể tạo ra 1 RAG Chatbot theo ý muốn của mình bằng cách sử dụng N8n. Đây là cách hiệu quả nhất hiện tại để tạo ra 1 chatbot trong ngắn hạn mà không cần quá nhiều kỹ năng lập trình. Các bạn có thể tìm thêm các template tại kho tempalte của chúng tôi tại đây