Cách lấy dữ liệu từ website bằng n8n crawler (JavaScript so với low-code)
Việc crawl dữ liệu là việc làm khó khăn, bằng cách dùng n8n crawler các bạn có thể lấy các dữ liệu này dễ dàng .Dữ liệu có cấu trúc đặc biệt có giá trị đối với các công ty và chuyên gia ở hầu hết các ngành công nghiệp, vì nó cung cấp nguyên liệu thô để đưa ra dự đoán, xác định xu hướng và hình thành đối tượng mục tiêu của họ.
Một phương pháp để lấy dữ liệu có cấu trúc, ngày càng trở nên phổ biến trong mười năm qua, là web scraping.
Trong bài viết này, chúng tôi sẽ khám phá hai cách tiếp cận khác nhau để thực hiện web scraping:
- Đầu tiên, chúng tôi sẽ trình bày cách trích xuất dữ liệu cụ thể từ một trang web bằng cách sử dụng mã JavaScript tùy chỉnh để tương tác trực tiếp với cấu trúc HTML.
- Sau đó, chúng tôi sẽ đi sâu vào n8n crawler, một công cụ mạnh mẽ ít mã code giúp đơn giản hóa quá trình web scraping và cung cấp tích hợp liền mạch với các dịch vụ khác như ChatGPT, Google Sheets, và Microsoft Excel.
Bằng cách so sánh hai phương pháp này, bạn sẽ hiểu rõ hơn về điểm mạnh và điểm yếu của chúng, từ đó có thể chọn công cụ phù hợp nhất với nhu cầu scraping của mình.
Như một phần thưởng, chúng tôi cũng sẽ khám phá cách kết hợp n8n crawler với sức mạnh của AI để trích xuất dữ liệu và thu được những hiểu biết sâu hơn từ dữ liệu đó.
Web scraping là gì?
Web scraping (còn gọi là thu hoạch dữ liệu web) là quá trình tự động trích xuất và thu thập dữ liệu từ một trang web. Phương pháp này hữu ích nếu bạn cần lấy dữ liệu có cấu trúc từ một trang web mà không có API hoặc nếu API cung cấp quyền truy cập hạn chế vào dữ liệu đó.
Trong thực tế, giả sử bạn muốn có một bảng tính chứa dữ liệu về 50 sản phẩm bán chạy nhất trong một cửa hàng trực tuyến, bao gồm tên sản phẩm, giá cả và tình trạng còn hàng.
Việc scraping trang web có hợp pháp không?
Pháp lý của web scraping khá phức tạp. Trong khi hành động này về cơ bản không phải là trái pháp luật, một số trang web rõ ràng cấm điều này trong điều khoản dịch vụ của họ. Những trang web khác có thể cho phép nhưng đặt ra giới hạn về loại và lượng dữ liệu mà bạn có thể thu thập.
Trước khi bắt đầu quá trình scraping, nên kiểm tra các điều khoản và chính sách quyền riêng tư của trang web mà bạn muốn lấy dữ liệu. Nếu không có đề cập nào, thì nên tra cứu file robots.txt trên trang web đó. File này chứa hướng dẫn về các khu vực của trang web được phép hoặc bị cấm để scraping và crawling. Ví dụ, để kiểm tra file robots.txt của IMDb, truy cập https://imdb.com/robots.txt.
Việc ưu tiên ToS hơn là tệp robots.txt là điều vô cùng cần thiết khi đánh giá tính hợp pháp của hoạt động scraping một website cụ thể. Tệp robots.txt nên được xem như một hướng dẫn thăm dò lịch sự hơn là một tài liệu pháp lý nghiêm ngặt. Các hoạt động scraping vi phạm điều khoản dịch vụ của website có thể dẫn đến bị cấm hoặc thậm chí bị xử lý pháp luật, đặc biệt nếu dữ liệu đã scraped được sử dụng cho mục đích thương mại.
Hoạt động scraping web hoạt động như thế nào?
Về cơ bản, quá trình scrape dữ liệu từ các trang web bao gồm 5 bước:
- Chọn URL (website) bạn muốn scrape.
- Gửi yêu cầu đến URL. Máy chủ phản hồi yêu cầu và trả về dữ liệu dưới dạng HTML.
- Chọn dữ liệu bạn muốn trích xuất từ trang web.
- Chạy mã để trích xuất dữ liệu đã chọn.
- Xuất dữ liệu theo định dạng dễ đọc (ví dụ, dưới dạng tệp CSV).
Làm thế nào để thực hiện web scraping?
Có nhiều lựa chọn khác nhau cho hoạt động scraping web, từ tiện ích mở rộng trình duyệt đến công cụ không mã và mã tùy chỉnh bằng các ngôn ngữ lập trình khác nhau.
Mặc dù các tiện ích mở rộng trình duyệt và các công cụ đơn giản hơn cung cấp một điểm vào thuận tiện cho các nhiệm vụ scraping web cơ bản, nhưng chúng còn hạn chế khi cần xử lý dữ liệu phức tạp hoặc tích hợp dữ liệu với các hệ thống khác.
Phần này sẽ tập trung vào các kỹ thuật scraping web nâng cao hơn giúp đem lại sự linh hoạt và kiểm soát tốt hơn.
Scraping web với mã tùy chỉnh
Nếu bạn quen với lập trình, bạn có thể tận dụng các thư viện được thiết kế đặc biệt cho scraping web trên nhiều ngôn ngữ lập trình khác nhau. Các lựa chọn phổ biến gồm:
- Python: Beautiful Soup, Scrapy, Selenium
- R: rvest
- JavaScript: Puppeteer
Các thư viện này cung cấp rất nhiều công cụ để lấy nội dung các trang web, phân tích HTML và XML, cũng như trích xuất chính xác dữ liệu bạn cần. JavaScript, vì là ngôn ngữ gốc của trình duyệt web, có thể tương tác trực tiếp với các trang web và các phần tử HTML, làm nó trở thành một lựa chọn tiện lợi cho một số nhiệm vụ scraping.
Ưu điểm chính của việc dùng mã tùy chỉnh và các thư viện là sự linh hoạt và kiểm soát mà nó mang lại cho nhà phát triển. Bạn có thể tùy chỉnh trình scraper của mình để nhắm tới dữ liệu cụ thể, xử lý cấu trúc website phức tạp và thực hiện logic tùy chỉnh cho việc làm sạch và chuyển đổi dữ liệu. Thêm vào đó, hầu hết các thư viện scraping web đều mã nguồn mở và miễn phí.
Scraping web với workflows n8n crawler
Mặc dù JavaScript cung cấp nền tảng vững chắc cho việc scraping web, việc quản lý các dự án lớn hơn, lên lịch các tác vụ hoặc tích hợp dữ liệu vào các hệ thống khác có thể gặp thách thức.
Để có một phương pháp tiếp cận dễ quản lý và mở rộng hơn, n8n cung cấp một lựa chọn không mã thân thiện người dùng. Hãy khám phá cách n8n crawler giúp bạn tự động hóa và nâng cao các quy trình scraping web thông qua giao diện trực quan, đồng thời xử lý phần mã nền tảng mà nếu không sẽ phải tự viết.
n8n crawler kết hợp sức mạnh của các thư viện với sự dễ dàng của các tiện ích mở rộng trình duyệt – và nó miễn phí để sử dụng. Bạn có thể xây dựng các quy trình tự động bằng cách sử dụng các nút cốt lõi như HTTP Request và HTML Extract để quét dữ liệu từ các trang web và lưu nó vào bảng tính.
Hơn nữa, bạn có thể mở rộng quy trình theo ý thích, ví dụ như gửi email đính kèm bảng tính, chèn dữ liệu vào cơ sở dữ liệu, hoặc phân tích và trực quan hóa dữ liệu trên bảng điều khiển.
Hãy cùng xem xét kỹ hơn cả hai phương pháp quét dữ liệu web!
Cách quét dữ liệu từ một trang web bằng JavaScript?
Hãy tạo một trình quét web cơ bản để giám sát giá của một mặt hàng trên Amazon sử dụng NodeJS và Puppeteer.
Điều kiện tiên quyết
- Cài đặt NodeJS
- Khởi tạo dự án NodeJS với lệnh
npm init -y - Cài đặt Puppeteer với lệnh
npm install puppeteer
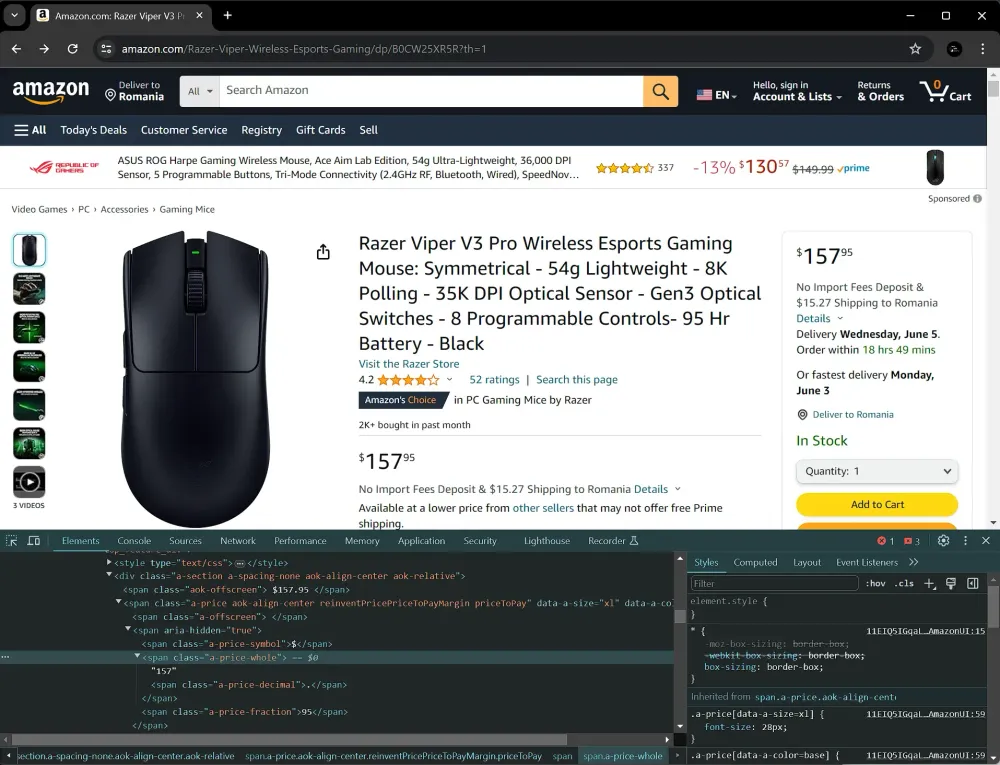
Bước 1: Xác định các phần tử mục tiêu
Trước khi viết mã, hãy kiểm tra trang sản phẩm trên Amazon. Nhấn chuột phải vào phần tử giá và chọn “Inspect” (hoặc “Inspect Element”) trong trình duyệt của bạn để xem cấu trúc HTML của nó. Ở đây, chúng ta cần xác định tên lớp hoặc ID duy nhất xác định phần tử giá. Trong trường hợp này, chúng ta sẽ nhắm vào phần tử có lớp a-price-whole.
Bước 2: Lấy nội dung trang
Đầu tiên, chúng ta nhập khẩu Puppeteer và xác định trang muốn quét:
const puppeteer = require("puppeteer"); const { KnownDevices } = require("puppeteer"); const iPhone = KnownDevices['iPhone 13'];
const targetURL = 'https://www.amazon.com/your-product'; KnownDevices sẽ được dùng để mô phỏng một thiết bị nhất định, trong trường hợp này là iPhone.
Bước 3: Khởi tạo Puppeteer và lấy nội dung trang
Chúng ta tạo một hàm có tên checkAmazonPrice, sau đó chỉ đạo Puppeteer mô phỏng một thiết bị iPhone, rồi truy cập vào URL của sản phẩm mà bạn muốn giám sát.
const checkAmazonPrice = async () => { // Khởi chạy trình duyệt không giao diện const browser = await puppeteer.launch();
// Tạo trang mới const page = await browser.newPage(); await page.emulate(iPhone);
// Truy cập trang web của bạn await page.goto(targetURL);
console.log('Trang đã tải xong!'); }; Bước 4: Xác định phần tử giá và lấy giá
Để debug trình quét của chúng ta, chúng ta có thể chụp ảnh màn hình của trang. Sau đó, đợi phần tử có lớp a-price-whole được tải lên trang, rồi lấy giá trị (đoạn innerText) của phần tử đó.
const checkAmazonPrice = async () => { // … // Chụp màn hình để kiểm tra
await page.screenshot({ path: 'screenshot.png' });
const element = await page.waitForSelector('.a-price-whole'); const elementPrice = await element.evaluate(el => el.innerText); const price = parseFloat(elementPrice); console.log('Giá:', price);
// Đóng trình duyệt await browser.close(); }; Chúng ta sau đó chuyển đổi nó thành số thực bằng cách sử dụng parseFloat, và ghi lại giá vào bảng điều khiển.
Cuối cùng, chúng ta đóng trình duyệt để tránh rò rỉ bộ nhớ.
Chúng ta có thể gọi hàm checkAmazonPrice. Đoạn script bây giờ sẽ trông như thế này:
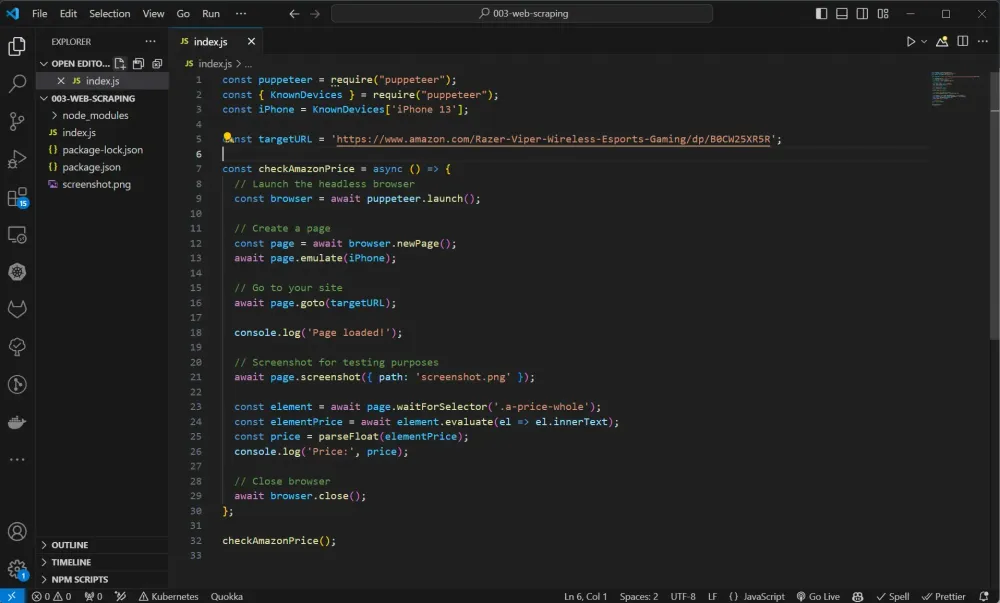
Sau đó, bạn có thể chạy script này bằng lệnh node index.js và quan sát giá của sản phẩm được ghi lại trong bảng điều khiển.

Bước 4: Lập lịch kiểm tra giá định kỳ
Chúng ta có thể chỉnh sửa script web scraping để chạy định kỳ, trong trường hợp này là hàng giờ:
// chạy ngay lập tức rồi mỗi giờ một lần
checkAmazonPrice(); setInterval(checkAmazonPrice, 1000 * 60 * 60); Bước 5: Giám sát bất kỳ thay đổi cấu trúc nào
Cấu trúc trang web của Amazon có thể thay đổi theo thời gian. Những thay đổi này có thể ảnh hưởng đến cách mã của bạn tương tác với trang web, đôi khi gây ra lỗi. Do đó, điều quan trọng là phải luôn cập nhật về bất kỳ sự thay đổi nào về cấu trúc để đảm bảo mã của bạn tiếp tục hoạt động đúng như dự định.
Để tránh làm quá tải máy chủ của Amazon, bạn cần chú ý đến số lượng yêu cầu gửi đi và phân bổ chúng hợp lý. Gửi một lượng lớn yêu cầu trong thời gian ngắn có thể gây quá tải cho máy chủ. Thông thường, các trang web có biện pháp bảo vệ để ngăn chặn quá nhiều yêu cầu cùng lúc. Gửi nhiều yêu cầu trong một khoảng thời gian ngắn có thể khiến yêu cầu của bạn bị chặn.
Mặc dù JavaScript cung cấp cách trực tiếp để trích xuất dữ liệu từ các trang web, việc xử lý các tác vụ ngoài mức trích xuất cơ bản có thể nhanh chóng trở nên phức tạp và tốn thời gian.
Nhưng đừng lo, nếu bạn đang tìm kiếm một phương pháp đơn giản và hiệu quả hơn, chúng tôi sẽ giới thiệu về web scraping với n8n crawler trong phần tiếp theo. Công cụ linh hoạt này giúp đơn giản hóa quá trình scraping qua giao diện trực quan, cho phép bạn xây dựng các luồng công việc mạnh mẽ bằng cách kết nối các node và hành động, đồng thời xử lý mã boilerplate phức tạp mà nếu không, bạn sẽ phải viết thủ công.
Cách tự động lấy dữ liệu từ một trang web với n8n crawler?
Chúng tôi sẽ hướng dẫn cách sử dụng n8n crawler để scrape một trang web, kích hoạt các hành động như gửi email thông báo, và lưu trữ dữ liệu trích xuất vào Google Sheets hoặc Microsoft Excel.
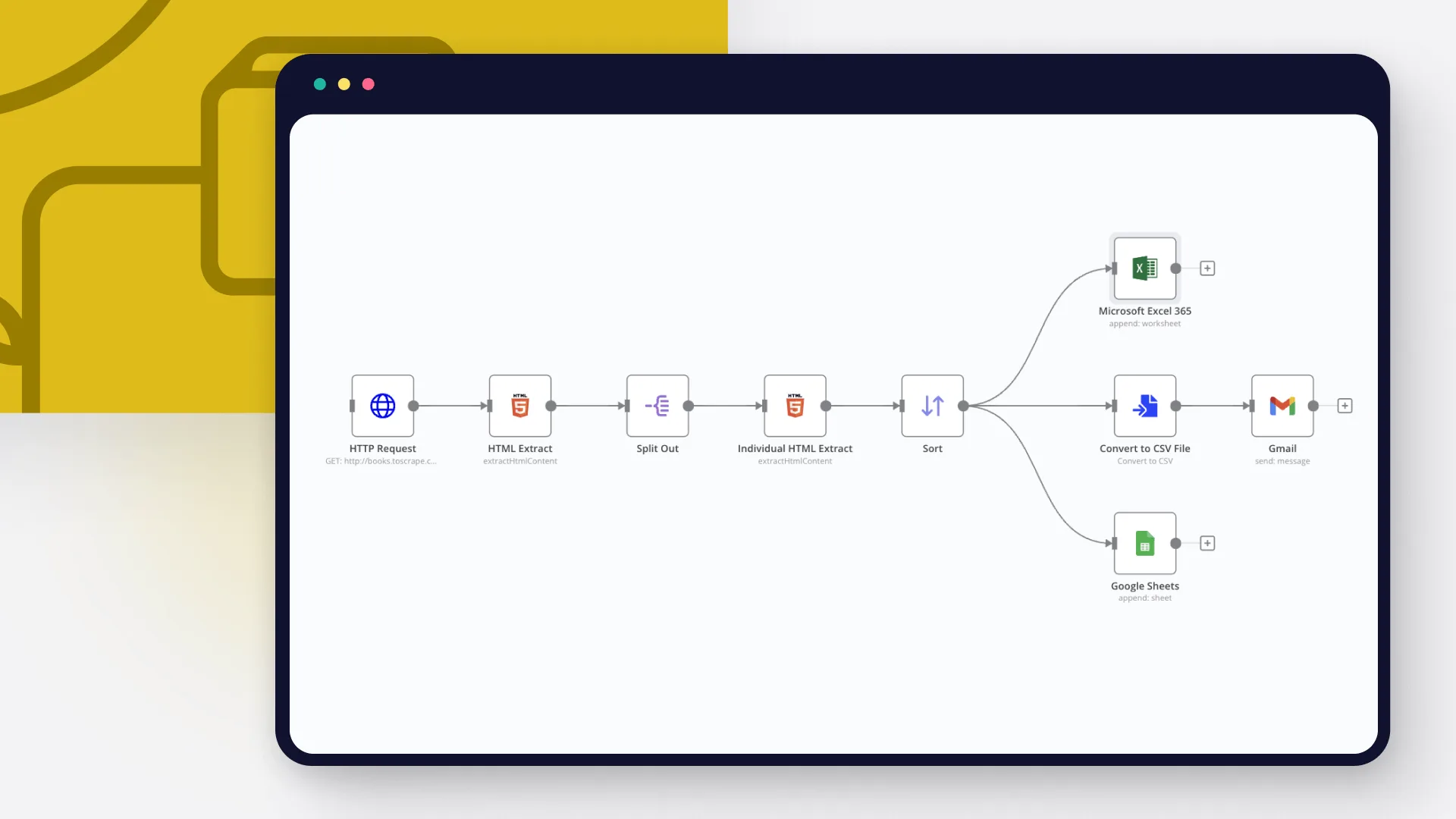
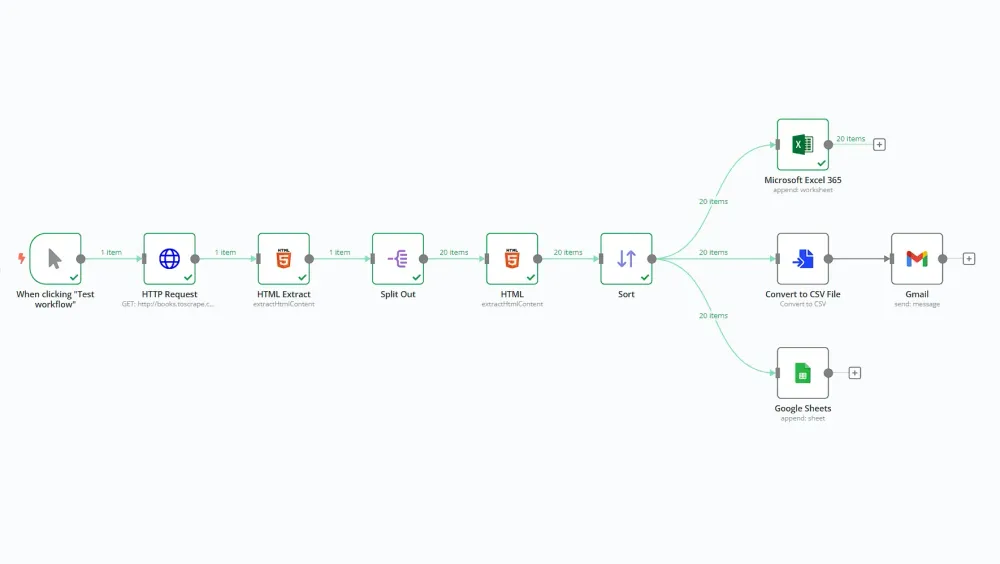
Hãy xây dựng một web scraper với ít mã nhất có thể bằng n8n crawler!
Quy trình này lấy thông tin về sách từ cửa hàng sách trực tuyến giả định http://books.toscrape.com, tạo ra một tập tin CSV, gửi nó đính kèm trong email và lưu trữ dữ liệu vào Google Sheets và Microsoft Excel 365.
Điều kiện tiên quyết
- Self host n8n
- Kiến thức cơ bản về HTML và CSS. Điều này hữu ích để biết cách điều hướng trang web và những phần tử nào cần chọn để trích xuất dữ liệu
- Tài khoản Google Cloud và thông tin xác thực
- Nếu sử dụng Microsoft Excel, bạn cần có tài khoản và thông tin xác thực của Microsoft Azure
Bước 1: Lấy dữ liệu từ website bằng n8n crawler
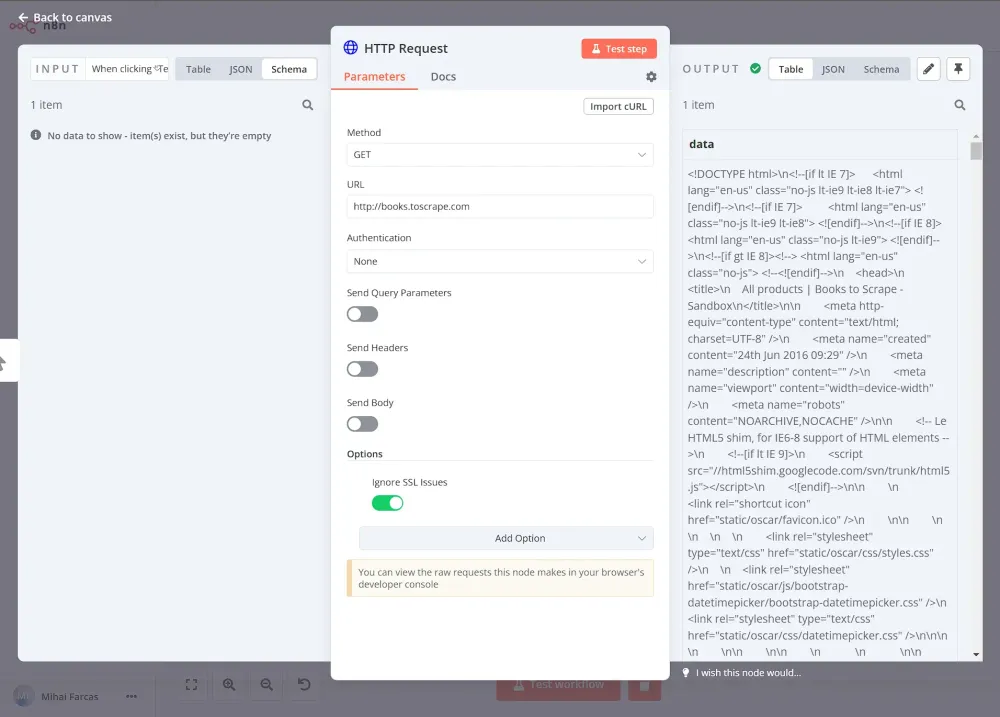
Trước tiên, bạn cần lấy dữ liệu từ trang web ở định dạng HTML. Để làm điều này, sử dụng nút yêu cầu HTTP với cài đặt GET làm Request Method và http://books.toscrape.com làm URL. Tiếp theo, bạn có thể cấu hình phản hồi: chọn String trong phần Response Format và đặt Property Name tùy ý. Trong ví dụ này, tôi đặt là data.
Sau đó, bạn có thể chạy nút, và kết quả sẽ trông như thế này:
Bước 2: Trích xuất dữ liệu từ website bằng n8n crawler
Bây giờ bạn đã có mã HTML của trang web, bạn cần trích xuất dữ liệu bạn muốn (trong trường hợp này, tất cả các sách trên trang). Để làm điều này, chúng ta có thể thêm nút HTML Extract và cấu hình nó như sau:
- Dữ liệu nguồn: JSON
- Thuộc tính JSON: data (Đây là tên thuộc tính đã đặt trong nút yêu cầu HTTP)
Chọn giá trị trích xuất:
- Khóa: books
- Chọn CSS:
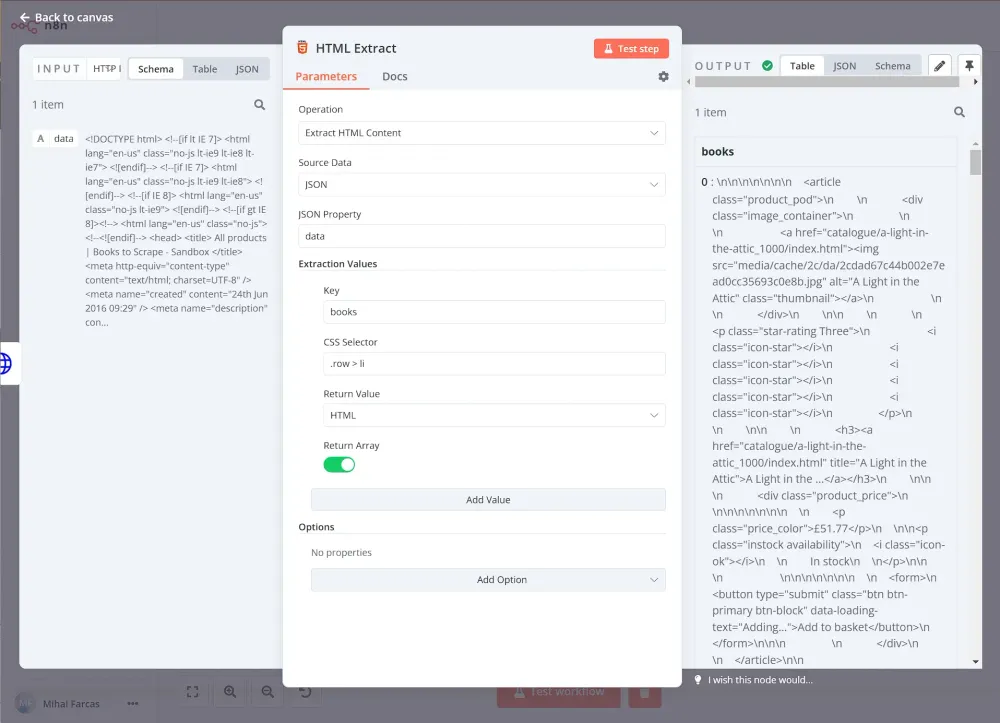
.row > li - Giá trị trả về: HTML
- Chọn Array Enabled (vì chúng ta sẽ lấy nhiều mục)
Bạn có thể lấy selector CSS bằng cách kiểm tra phần tử của trang, giống như chúng ta đã làm trong phần JavaScript của hướng dẫn này. n8n crawler hỗ trợ tất cả các selector CSS và các phép kết hợp, trong trường hợp này .row > li chọn tất cả các mục li nằm trong phần tử có lớp “row”.
Khi bạn chạy nút, kết quả sẽ như thế này:
Tiếp theo, chúng ta cần xử lý từng phần tử trả về từ các bước trước. Để làm điều này từng cái một, chúng ta sử dụng nút Split Out. Đặt Fields To Split Out thành books và để các thiết lập còn lại theo mặc định.
Khi bạn chạy nút, kết quả sẽ như thế này:
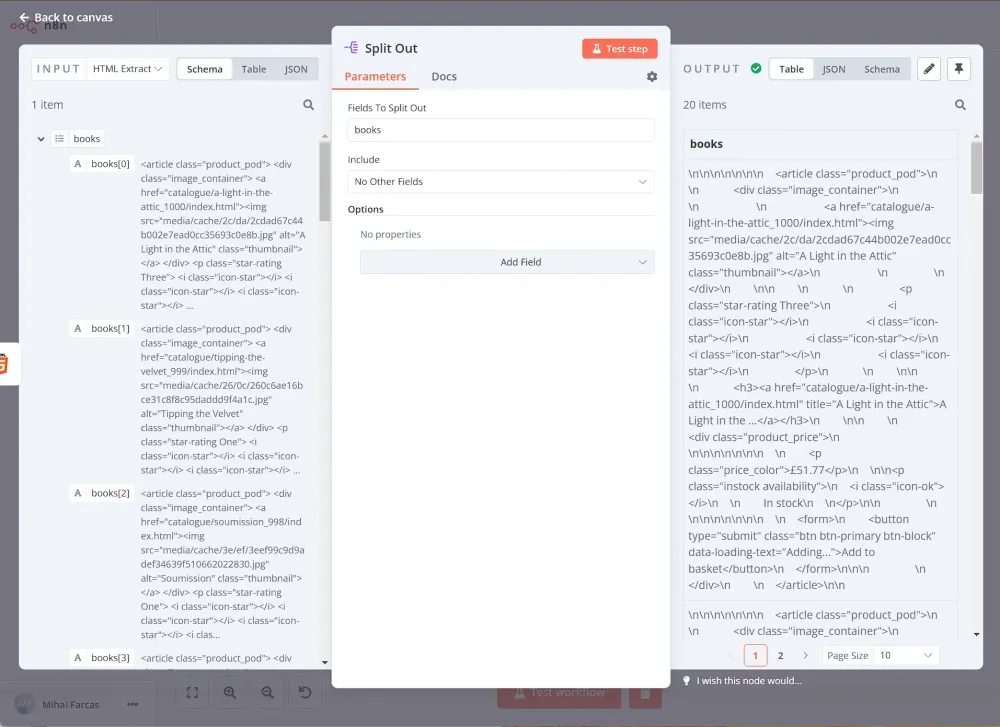
Bây giờ, bạn đã có danh sách 20 mục (sách), bạn cần trích xuất tiêu đề và giá từ mã HTML của chúng. Để làm điều này, chúng ta sẽ dùng thêm một nút HTML khác với các tham số sau:
- Dữ liệu nguồn: JSON
- Thuộc tính JSON: books
Giá trị trích xuất:
- Chìa khóa: title
- Chọn CSS:
h3 - Giá trị trả về: Text
- Chìa khóa: price
- Chọn CSS:
article > div.product_price > p.price_color - Giá trị trả về: Text
Khi bạn thực thi nút, kết quả sẽ trông như thế này:
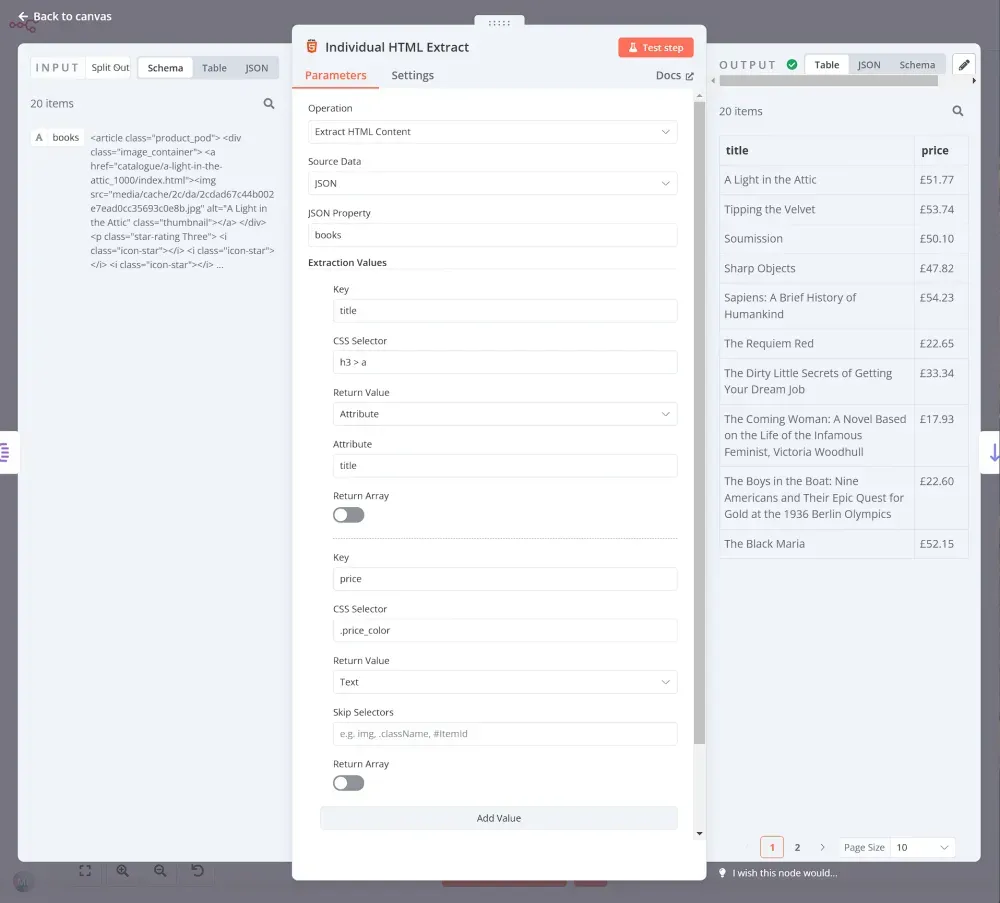
Bước 3: Sắp xếp dữ liệu bằng n8n crawler
Hãy sắp xếp các cuốn sách theo giá của chúng theo thứ tự giảm dần. Để làm điều này, chúng ta có thể sử dụng nút Sort. Chúng ta để Kiểu là Đơn giản và dưới Các Trường Để Sắp Xếp chúng ta đặt Tên Trường thành price và Thứ tự là Giảm dần.
Khi bạn thực thi nút, kết quả sẽ trông như thế này:
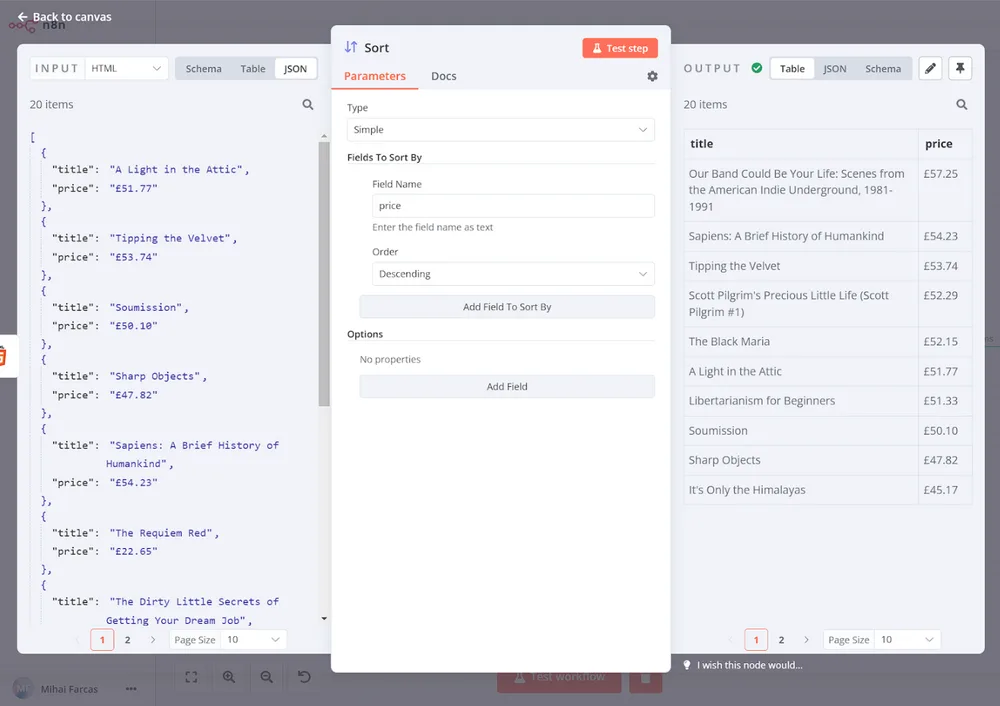
Bước 4: Ghi dữ liệu đã thu thập vào bảng tính bằng n8n crawler
Bây giờ, sau khi bạn đã thu thập dữ liệu theo cách có cấu trúc, bạn sẽ muốn xuất nó thành một tệp CSV. Để làm điều này, hãy sử dụng nút Chuyển thành Tệp. Từ menu thả xuống Hoạt Động chọn Chuyển thành CSV, và đặt Đặt Tệp Đầu Ra Trong Trường thành data.
Khi bạn thực thi nút, kết quả sẽ trông như thế này:
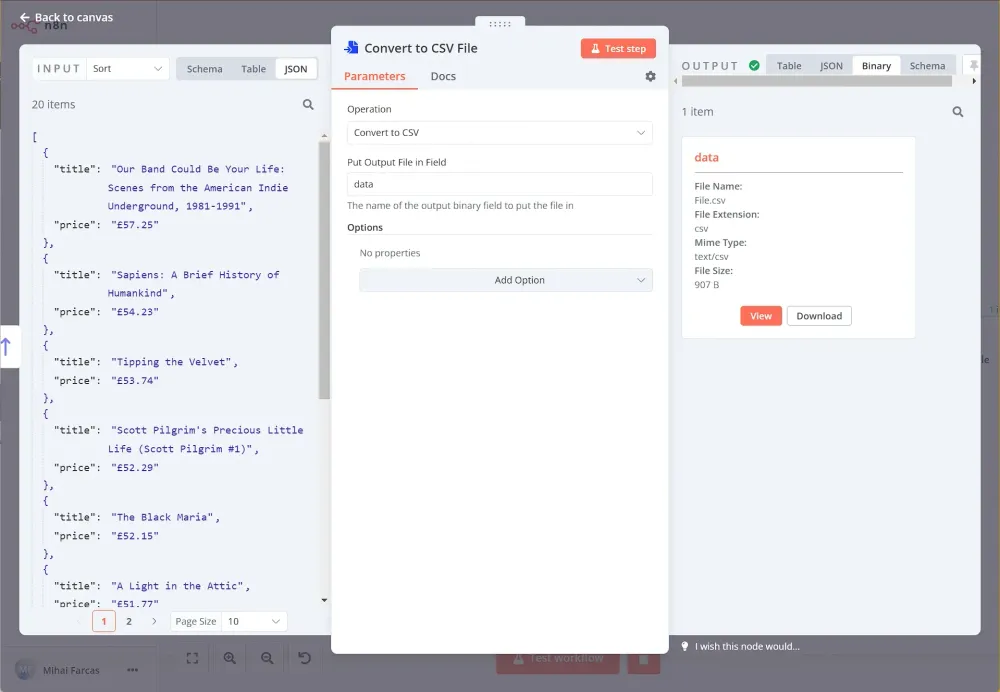
Và đơn giản như vậy! Bây giờ bạn có một tệp CSV có thể tải về hoặc thậm chí tốt hơn, chúng ta có thể gửi nó qua email.
Bước 5: Gửi bộ dữ liệu qua email bằng n8n crawler
Để gửi tệp CSV dưới dạng tệp đính kèm qua email, chúng ta có thể sử dụng nút Gmail với các tham số sau:
- Tài nguyên: Message
- Hoạt động: Gửi
- Đến: địa chỉ email bạn muốn gửi đến
- Tiêu đề: bookstore csv (hoặc bất kỳ tiêu đề nào bạn muốn)
- Thông điệp: Chào, đây là dữ liệu thu thập từ hiệu sách trực tuyến!
Và đối với Các tùy chọn / Tệp đính kèm, thiết lập như sau:
- Tên Trường Đính kèm: data (đây là tên của thuộc tính dạng nhị phân được đặt trong nút convert to File)
Bây giờ, đảm bảo khi bạn thực thi nút, kết quả sẽ trông như thế này:
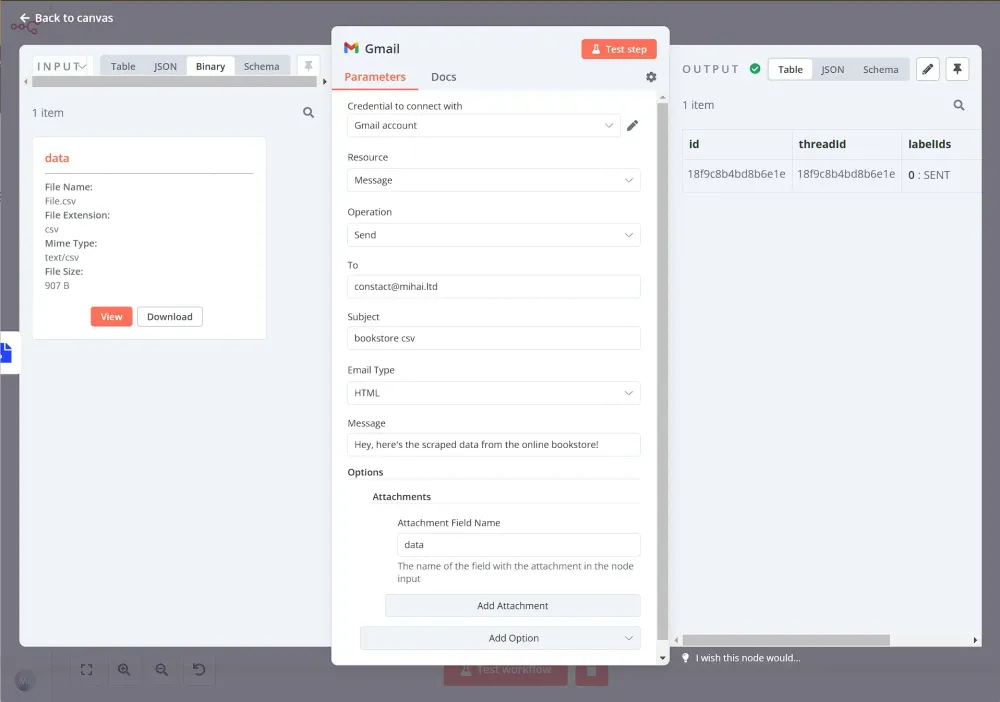
Bây giờ, chỉ cần kiểm tra hộp thư đến của bạn – bạn sẽ nhận được một email chứa tệp CSV!
Bước 6: Lưu dữ liệu vào Google Sheets hoặc Microsoft Excel bằng n8n crawler
Một tùy chọn khác là lưu dữ liệu đã thu thập vào Google Trang tính. Bạn có thể thực hiện điều này bằng cách thiết lập nút Google Sheets như sau:
- Thông tin xác thực để kết nối: thông tin đăng nhập tài khoản Google Cloud của bạn.
- Tài nguyên: Sheet Within Document
- Hoạt động: Thêm hàng
- Document: chọn một tài liệu từ danh sách thả xuống. Hoặc bạn có thể chọn một sheet theo URL hoặc ID.
- Sheet: chọn sheet từ danh sách thả xuống. Hoặc bạn có thể chọn sheet theo URL, theo ID hoặc theo tên. Chế độ ánh xạ cột: sử dụng Ánh xạ tự động cho hầu hết các trường hợp.
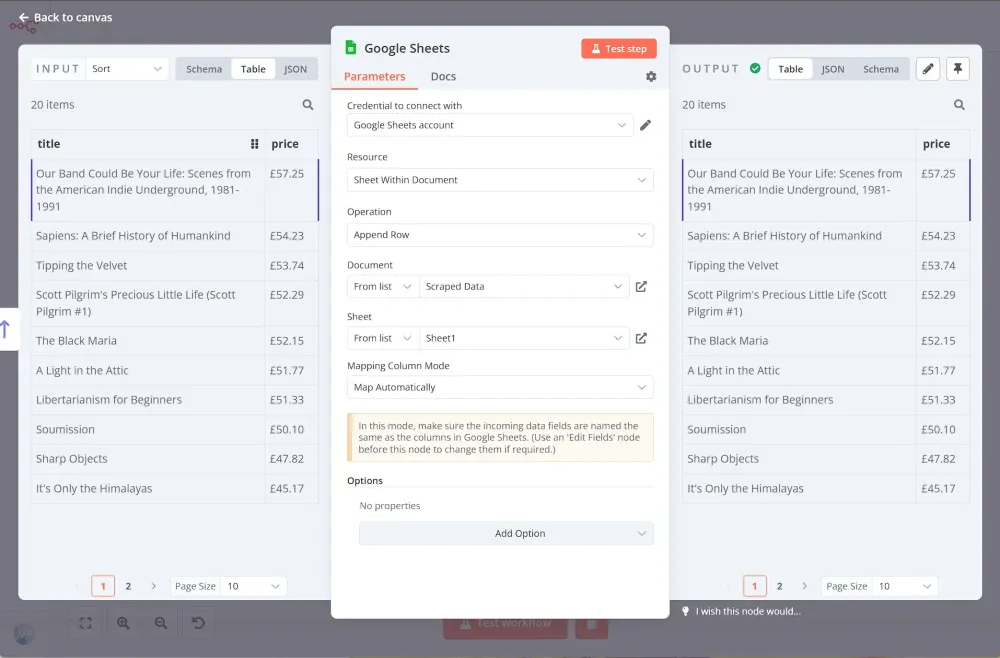
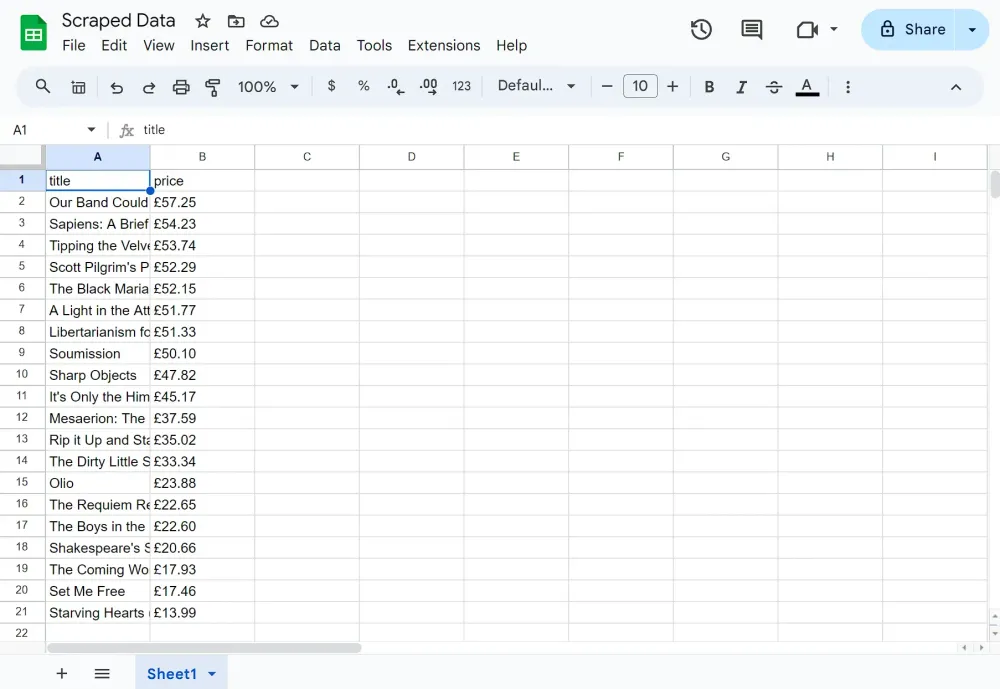
Sau khi thực thi nút, bạn sẽ thấy tất cả các cuốn sách và giá của chúng trong Google Sheet.
Nếu bạn thích làm việc với Microsoft Excel, n8n crawler cũng tích hợp rất dễ dàng với nó. Thay vì sử dụng node Google Sheets, bạn sẽ sử dụng node Microsoft Excel thay thế.
Điều này yêu cầu một chút cài đặt thêm, trước tiên bạn cần thiết lập thông tin đăng nhập Microsoft Azure với quyền Microsoft Graph.
Tiếp theo, tạo một workbook Excel và lấy ID của nó từ URL. Định dạng của URL sẽ trông giống như https://onedrive.live.com/edit?id=XXXXXXXXXXXXXXXX&. ID sẽ nằm giữa id= và &.
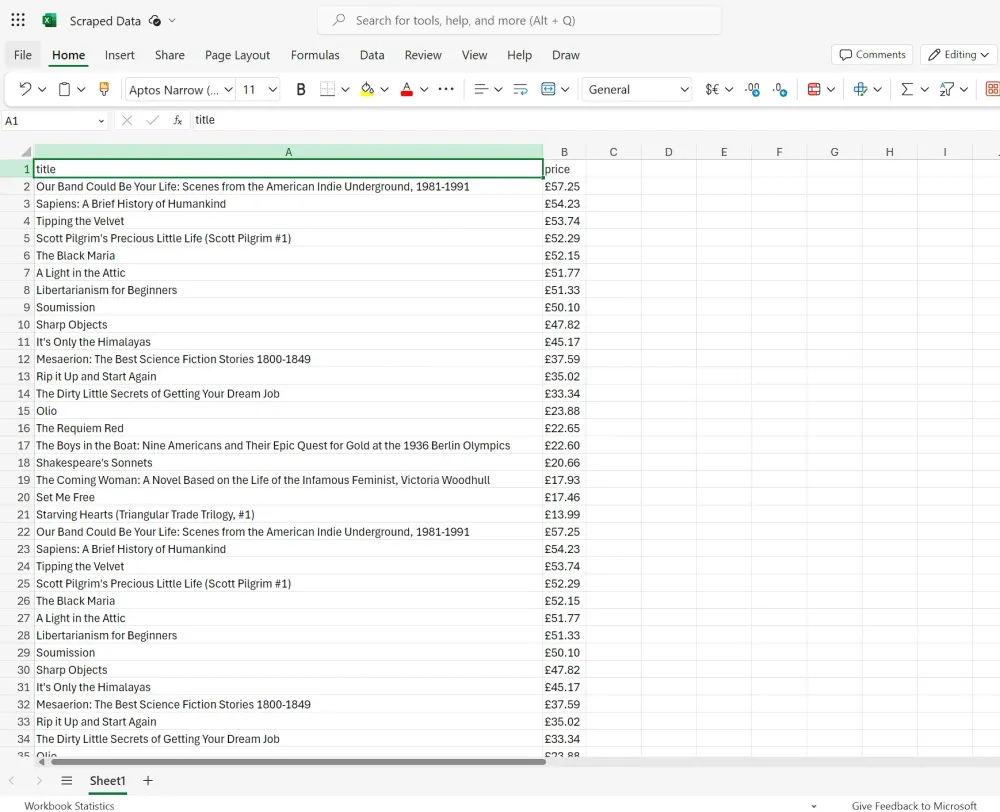
Không giống như Google Sheets nơi chúng ta không cần định dạng cụ thể, ở đây chúng ta cần tạo các tiêu đề cột, nếu không việc thêm dữ liệu vào sheet sẽ không hoạt động. Trong trường hợp này, chúng ta có thể thêm tiêu đề là Title và Price làm tiêu đề cột. Workbook trống sẽ trông như thế này:
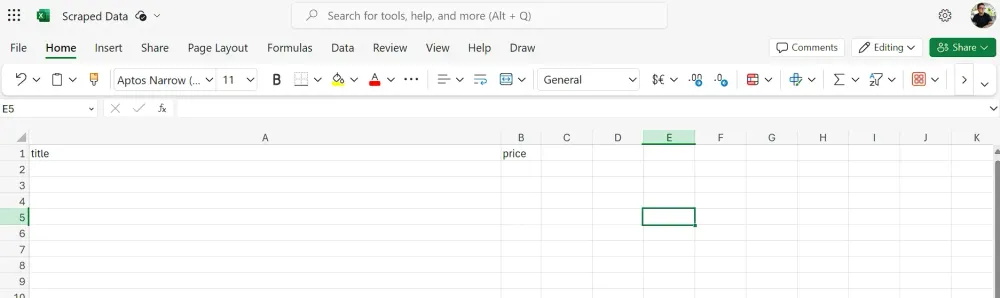
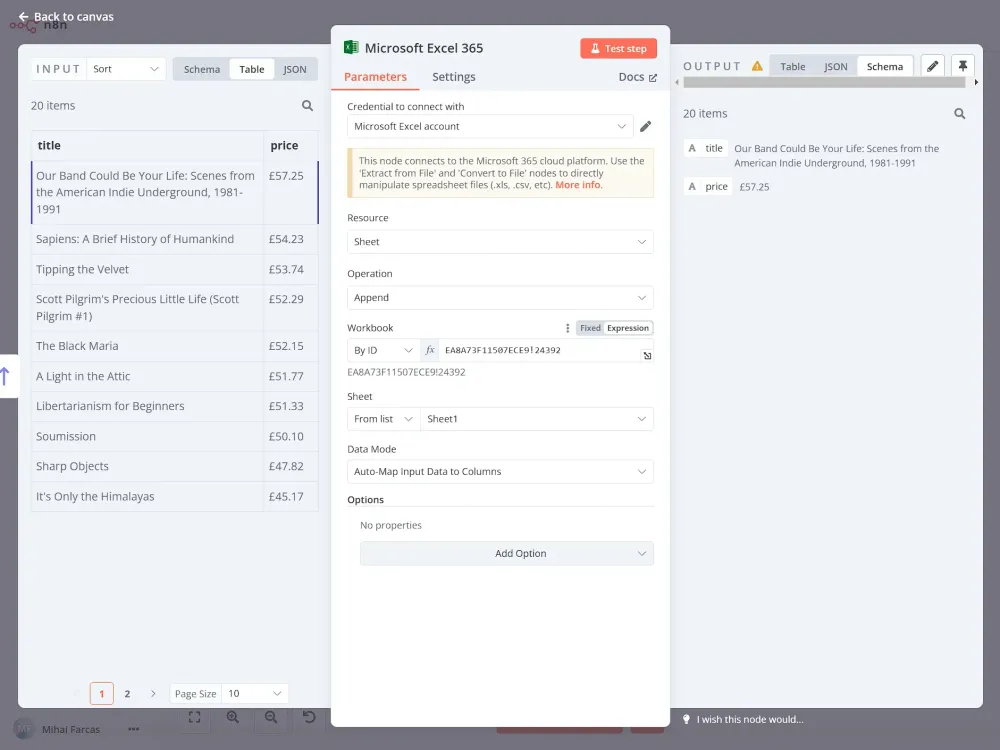
Tiếp theo, chúng ta cần cấu hình node Microsoft Excel như sau:
- Resource: Sheet
- Operation: Append
- Workbook (Theo ID): Workbook ID
- Sheet: chọn một sheet từ danh sách Data Mode: Auto-Map Input Data to Columns
Sau khi chạy node, bạn sẽ thấy dữ liệu được thêm vào sheet Excel:
- Resource: Sheet
- Operation: Append
- Workbook (Theo ID): Workbook ID
- Sheet: chọn một sheet từ danh sách Data Mode: Auto-Map Input Data to Columns
Sau khi chạy node, bạn sẽ thấy dữ liệu được thêm vào sheet Excel:
Thêm: ChatGPT có thể scrape web không?
Mặc dù khả năng scraping web của n8n crawler rất ấn tượng riêng, sự tích hợp của nó với các công cụ AI như ChatGPT mở ra nhiều khả năng hơn nữa.
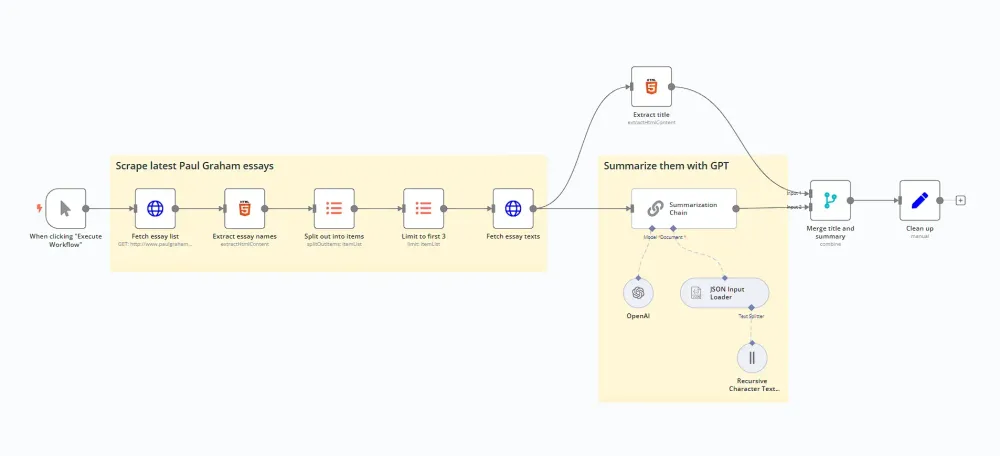
Trong phần này, chúng ta sẽ khám phá một quy trình làm việc mà scrape dữ liệu và sử dụng AI để tóm tắt nội dung.
Dưới đây là tổng quan về một quy trình làm việc nhằm scrape và tóm tắt các trang web với AI:
Bước 1: Lấy nội dung trang bằng n8n crawler
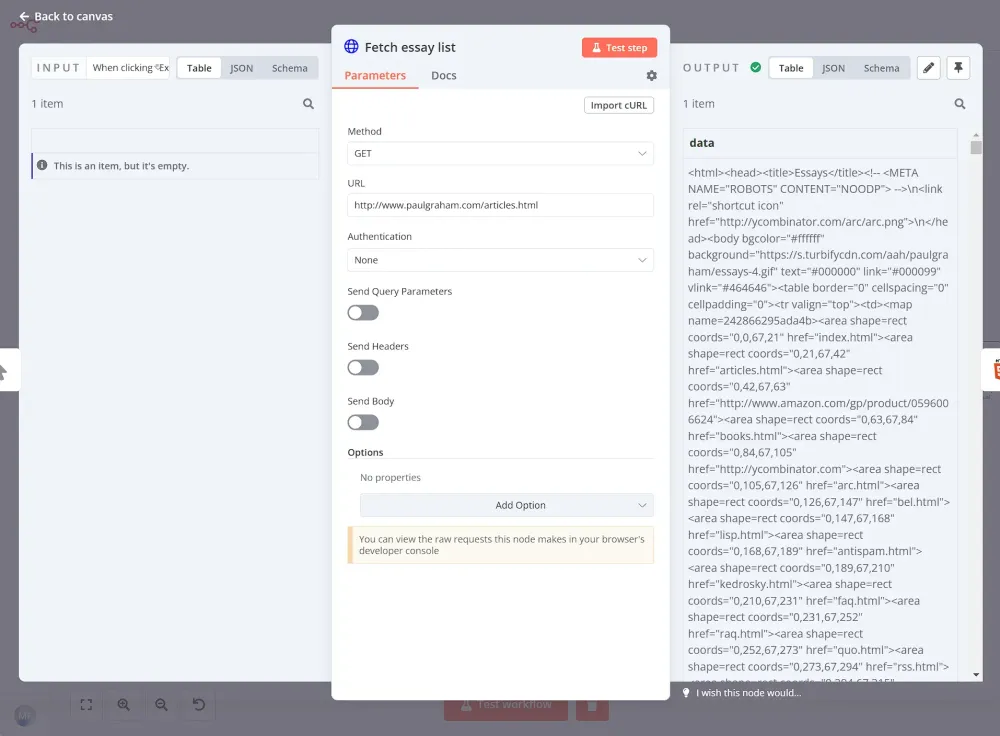
Tương tự ví dụ trước, chúng ta sẽ scrape dữ liệu sách từ cửa hàng trực tuyến http://books.toscrape.com. Đầu tiên, chúng ta sử dụng node Request HTTP để lấy nội dung của trang, như sau:
Bước 2: Lấy 3 bài luận đầu tiên bằng n8n crawler
Sau đó, chúng ta sử dụng node HTML Extract để phân tích HTML kết quả, và lấy tiêu đề bài luận bằng cách sử dụng bộ chọn CSS table table a.
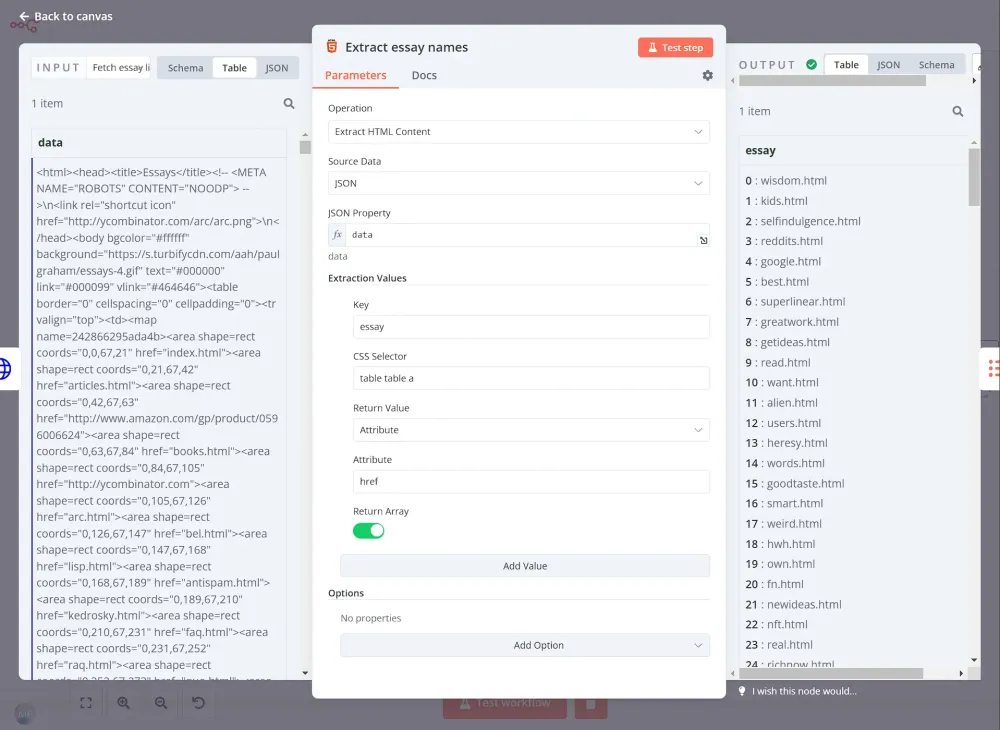
Tương tự quy trình trước, chúng ta cần dùng node Split Out để xử lý từng bài luận một. Đặt Fields To Split Out thành essay và để các phần khác theo mặc định.
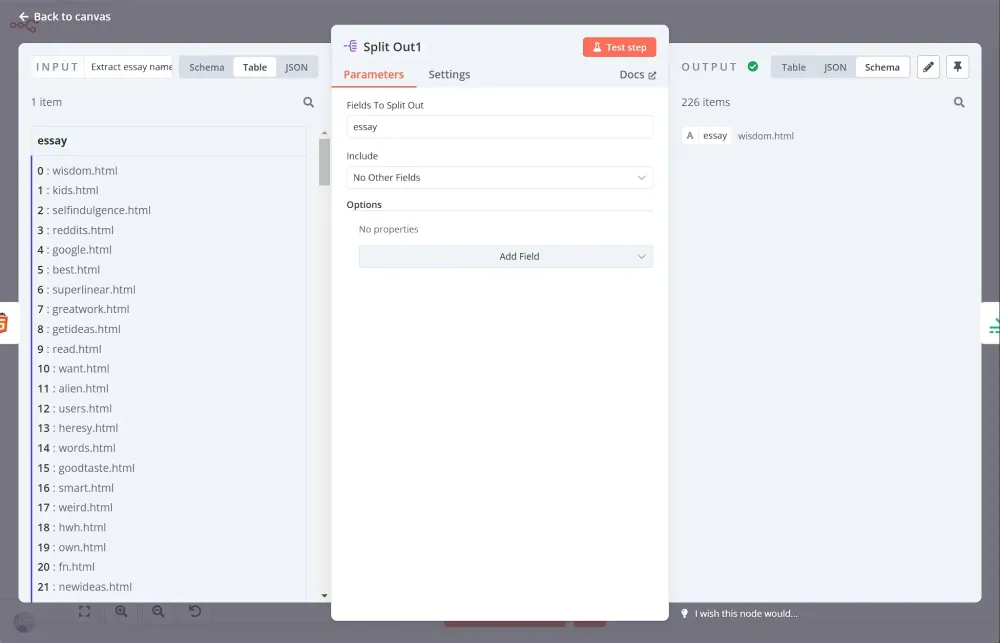
Tiếp theo, dùng node Limit để chỉ lấy 3 bài luận đầu tiên:
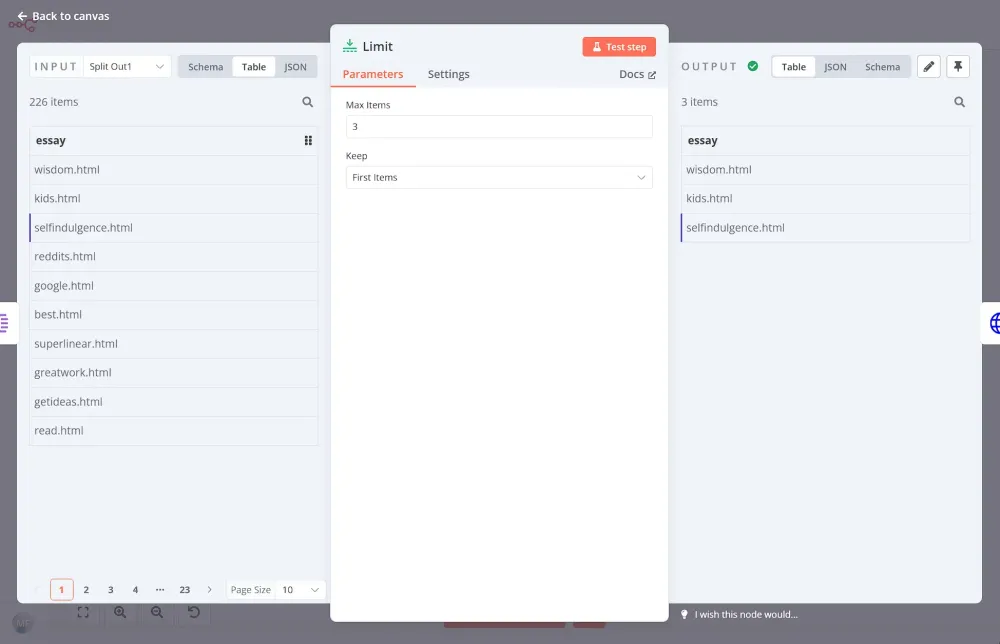
Bước 3: Trích xuất nội dung và tiêu đề bài luận bằng n8n crawler
Node trước đó chỉ cung cấp cho chúng ta URL của từng bài luận. Sử dụng một node yêu cầu HTTP khác, chúng ta có thể truy cập trang và trích xuất nội dung tại đó:
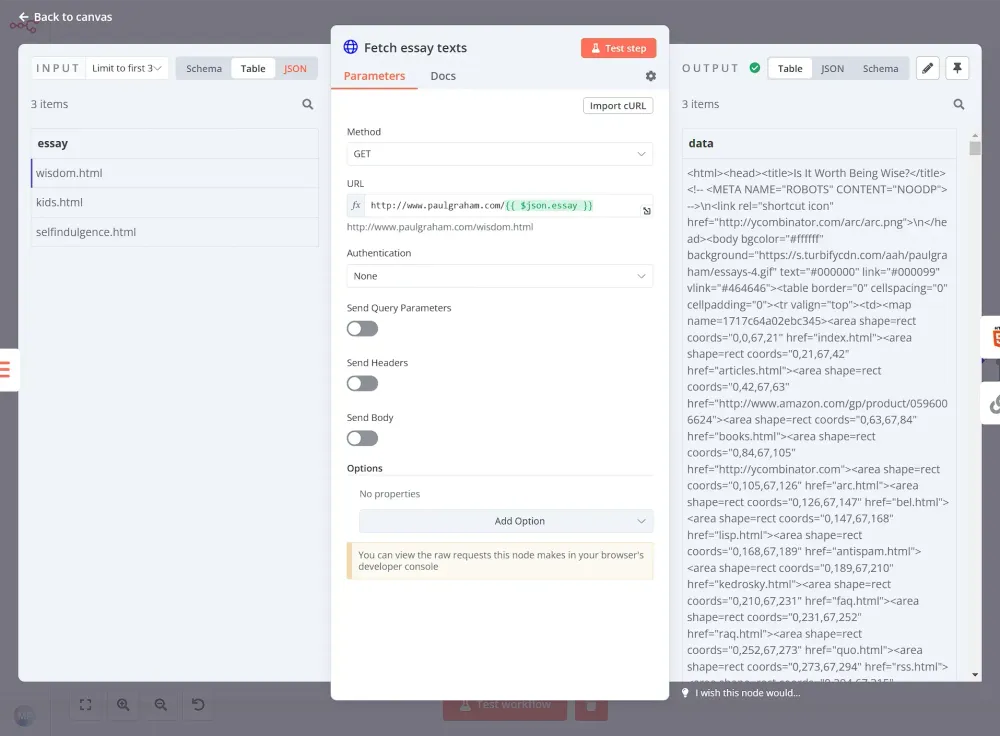
Sau khi nhận được nội dung của từng trong 3 bài luận, chúng ta muốn trích xuất tiêu đề của mỗi bài. Thông tin này sẽ hữu ích khi soạn thảo kết quả cuối cùng. Để làm điều này, chúng ta sẽ sử dụng một node HTML Extract khác:
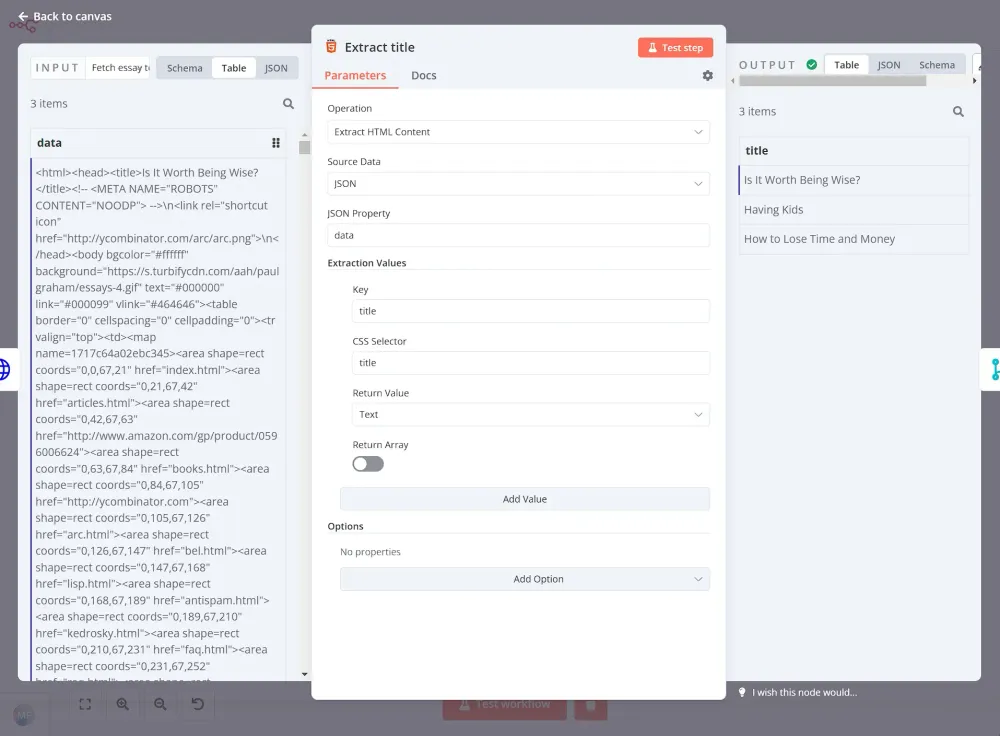
Bước 4: Gửi nội dung tới ChatGPT để tóm tắt bằng n8n crawler
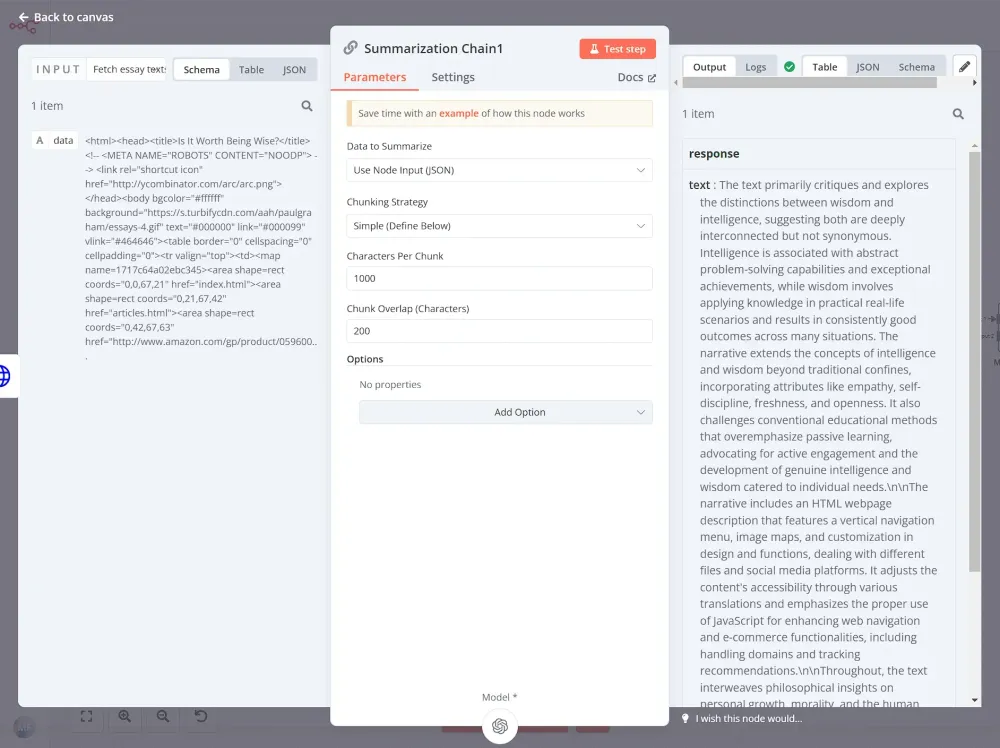
Đây chính là nơi phép thuật AI bắt đầu. Node Summarization Chain, một node đặc biệt trong n8n crawler, giúp đơn giản hóa quá trình sử dụng các mô hình ngôn ngữ AI như ChatGPT để tạo ra các bản tóm tắt. Chúng ta sẽ kết nối node này vào luồng công việc của mình, cung cấp nội dung bài luận đã được trích xuất. Node Summarization Chain sẽ lo liệu việc giao tiếp phức tạp với mô hình AI, và trả về một bản tóm tắt ngắn gọn cho mỗi bài luận.
Ở đây, chúng ta có thể để mọi thứ ở chế độ mặc định:
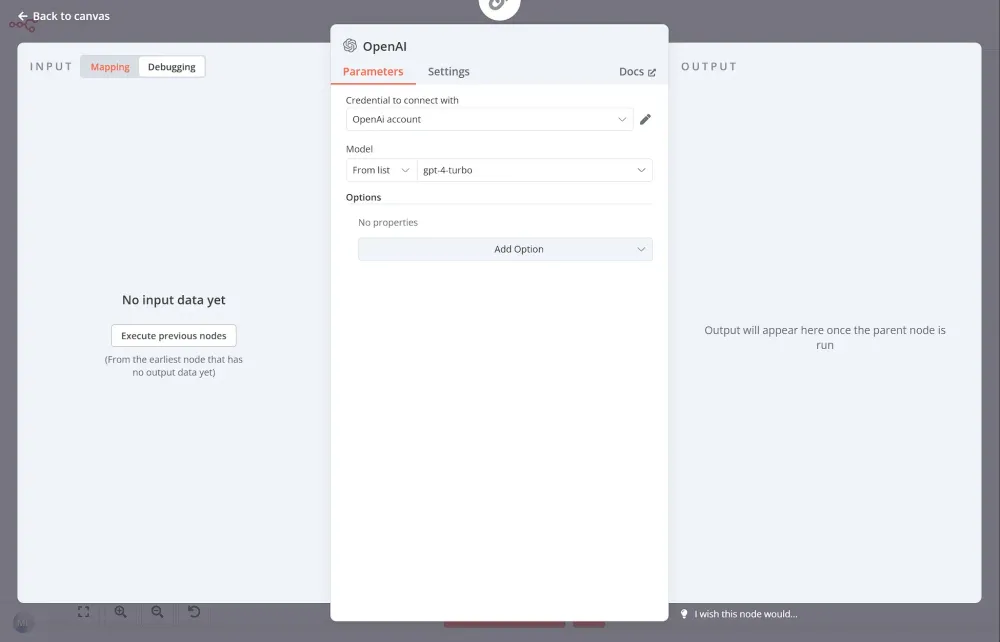
Node Summarization Chain yêu cầu một mô hình AI. Bạn có thể sử dụng tích hợp OpenAI bằng cách thiết lập thông tin xác thực OpenAI rồi chọn Model từ danh sách. Trong trường hợp này, chúng tôi chọn gpt-4-turbo:
Bước 5: Nối tiêu đề và bản tóm tắt lại với nhau bằng n8n crawler
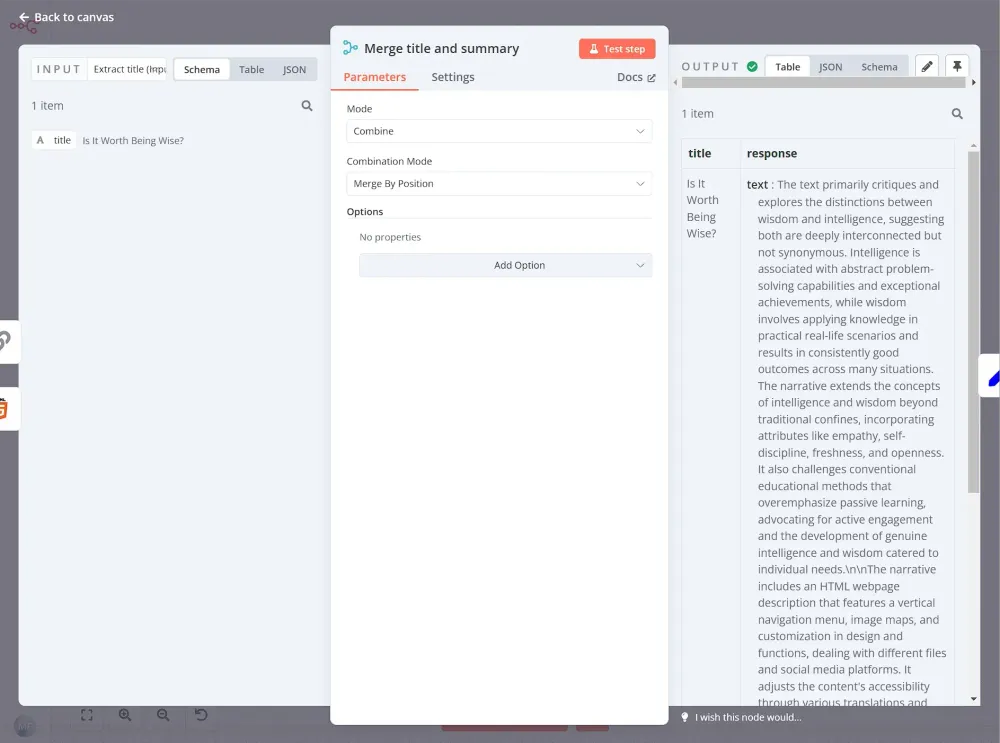
Cuối cùng, chúng ta sẽ sử dụng node Merge để kết hợp tiêu đề ban đầu của bài luận với các bản tóm tắt do AI tạo ra. Kết quả là một tập dữ liệu được tổ chức gọn gàng, sẵn sàng để xử lý thêm hoặc xuất ra.
Kết luận n8n crawler
Bây giờ bạn đã nắm được những điều cơ bản về web scraping: nó là gì, hoạt động như thế nào, và cần ghi nhớ điều gì khi quét dữ liệu từ các trang web. Bạn cũng đã học cách trích xuất dữ liệu từ một trang web bằng JavaScript và luồng công việc low-code của n8n crawler.
Với n8n crawler, không còn cần phải viết từng dòng mã để lấy dữ liệu bạn cần nữa. Bạn có thể sử dụng n8n crawler để tự động hóa quá trình scraping HTML của bạn và gửi dữ liệu đến các nơi thích hợp. Hơn nữa, bạn có thể thêm các logic điều kiện, mã tùy chỉnh, và kết nối các tích hợp khác để thiết lập các luồng công việc giúp tăng năng suất của mình.
Tiếp theo là gì?
Sẵn sàng nâng cao kỹ năng tự động hóa của bạn hơn nữa chưa? Đây là những gì bạn có thể làm tiếp với n8n crawler
- Xem một luồng công việc phức tạp hơn, trích xuất dữ liệu từ một trang web nhiều trang, và đọc về chiến lược của nó.
- Xem trang luồng công việc để có thêm ý tưởng về tự động hóa.
Các bạn có thể tham khảo thêm các template khác tại đây.